Advanced workflow alerting - Step 2: Reducing error fatigue with an error reporting dashboard


This post is the second in a two-part series about managing workflow alerts. The first covered getting a Slack notification when an error happens. This time, we’ll get a bit more advanced and develop a dashboard for users who need to manage a relatively high volume of workflow tasks.
I don’t know about you, but keeping up with the onslaught of emails, chats, text messages, push notifications, and woofs is a serious battle for me (my SLA for replying to Slack messages is creeping up on 48 hours). When I started managing the Growth Ops team at Tray.io, I started feeling the pain our resident star operations manager knew all too well - alert fatigue!
Like many operations teams, we own several mission-critical processes, and our portfolio is changing and growing daily.
Even though we automate many processes with a General Automation Platform to do more, faster, we also need to monitor the progress of our workflows. In many cases, we use Slack to send ourselves alerts on what's working, what isn't, and where issues may occur.
Unfortunately, the repetitive nature of Slack alerts can lead even the most vigilant operations team to lose sight of how often workflows are failing and why sometimes.
Error dashboard to the rescue!
A dashboard helps us understand which workflows are experiencing errors, how often the errors happen, and which parts of the workflows are problematic.
Dashboards help us monitor mission-critical problems in daily operations and prioritize less-critical issues for cleanup at a later date. In this example, we also use our customer data platform Segment as well as our data warehouse Redshift and our analytics platform Sisense, formerly known as Periscope Data.
We can implement our dashboards by extending our original workflow solution using the following:
- A Segment Track operation: To log error events in our alerting workflow
- A Segment warehouse destination: To sync events to our data warehouse
- A data warehouse: To store our error data (read more about how to use Redshift)
- A Sisense dashboard: To create our charts
Don’t have quite the same stack here? Fear not, you can easily tweak the concepts here using the Tray Platform for a variety of architectures and solutions, which I’ll do my best to point out along the way!
Our dashboard is quite simple. There’s just two charts and two filters:
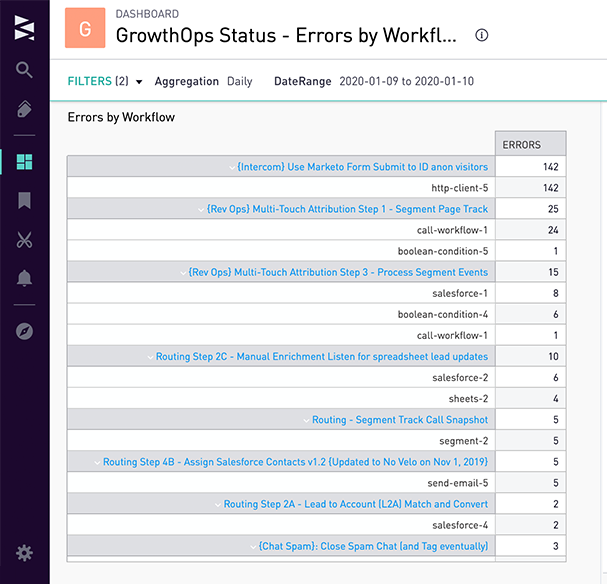
Errors by Workflow: A cohort chart, which has a rollup count of errors by workflow name and error step.
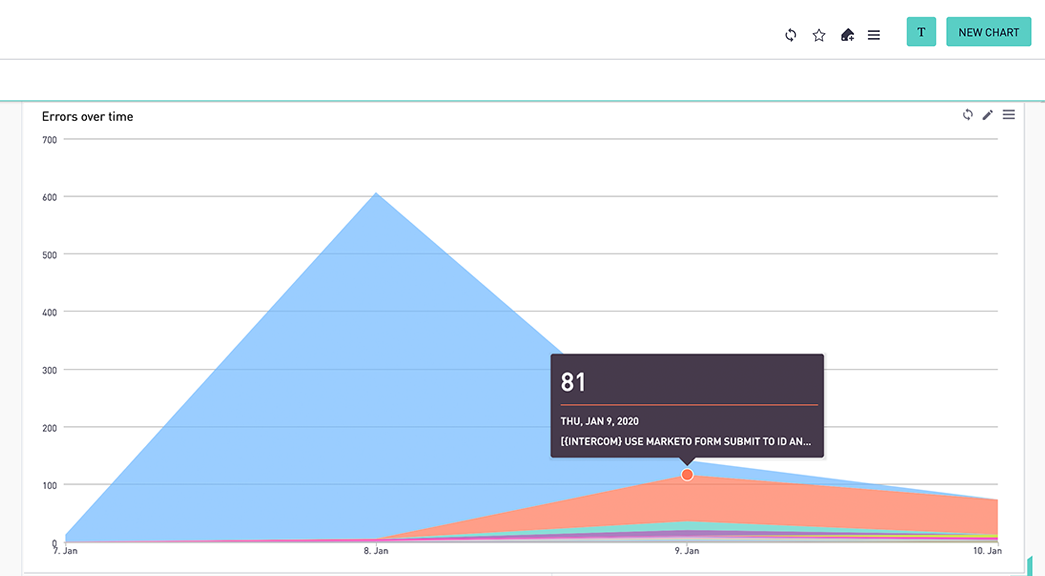
Errors Over Time: An area timeseries chart which charts error count by workflow over the aggregation type (such as daily, weekly, or monthly) and date range we choose in the filters.


Setting up an Alerting Workflow
Using the Tray Platform’s Segment connector, we can pass error data to our warehouse by dragging it into our alerting workflow and selecting the “Track Event” operation:

We can give our event a common-sense name (like “workflowError”) and pass the entire contents of the trigger output object into the properties object of the event using JSON path:

Our team uses a dedicated Segment source for various workflow analytics we track, which in turn syncs to our data warehouse every hour:

If you don’t use Segment, no problem! Instead, use one of our data warehouse connectors to insert each row directly:

Don’t see your data warehouse above? Still, no problem! Use our toolkit to make an "insert row" call via your provider's REST APIs.
The table schema Segment creates ends up looking like this in our data warehouse:

With error data in our data warehouse, we can write a basic query to see what they look like:

Our query generates a table of errors over the last week ranked by frequency:

We’ll need to make a few adjustments to hyperlink our workflow name to its own logs in the cohort chart, as well as to take advantage of the aggregation and date range filters for the timeseries chart:

Protip! Leverage SQL snippets so you can write a query once and use it in multiple charts. Save your SQL snippet and give it a name that’s easy to understand and remember:

Create a new dashboard in Sisense and “enable filters” in the top-right hamburger menu:

Configure a new cohort chart like this (notice that we call the SQL snippet by wrapping the snippet name in square brackets):

As your data syncs via Segment, rather than watching the Slack channel like a hawk, you can now check this chart throughout the day to see if any mission-critical problems pop up that actually need your attention!
What about errors that pile up over time? We'll need to look at larger timeframes on the cohort chart. We can use a trendline chart using the same query:

Because the Tray Platform is so flexible, you can easily tweak your alerting workflows and architecture as you think of other interesting ways to fine-tune your alerting processes. For example, we can take advantage of Sisense’s SQL alerts or passing error data to something like Datadog, New Relic, or PagerDuty.
You’re now a lean, mean, alerting machine. Let's get to work, my friends! A little time upfront will save hours of headaches down the line!
I hope you found this post helpful - if you’re a customer, feel free to reach out to me in our customer Slack channel if you have questions (your CSM can grant you access). Alternately, if you'd like to see more of the Tray Platform in action, sign up for a weekly demo.