CSV Editor 7.0
A connector for manipulating CSV files (formerly known as CSV Processor) with the CSV Editor core connector
OverviewCopy
The CSV Editor allows you to manipulate CSV files in various ways.
You can import and edit CSV files from outside your workflow, or you can dynamically create the CSV files from data being pulled in from previous workflow steps.
Think of the CSV Editor as a data storage connector for spreadsheets! It is most commonly used as a means of temporarily storing and manipulating structured information, en route from one service to another.
CSV Editor templatesCopy
Please note that we have the following CSV templates available:
Create a CSV file from JSON array
Generates a CSV file from a JSON list of objects then (optionally) sends the CSV via email

Extract Salesforce records and email as CSV
Paginates through any number of Salesforce records and emails the resulting CSV

Extract AWS S3 data as JSON
Generates a JSON list of data pulled from a CSV or XLSX file in AWS
Extract and transform CSV data from AWS S3
Extracts data from a CSV in AWS S3 and prepares the data to be easily interacted with
These will give you pre-configured best practice ways of creating and manipulating CSVs.
However, it is strongly recommended that you read the contents of this page to understand basic usage and principles of the CSV Editor.
Importing CSV filesCopy
Please see our section on Managing CSV files for guidance on the different ways in which you can import CSV files to your workflows
CSV Editor vs CSV ReaderCopy
The CSV Reader is much more efficient at reading large files and file content. It uses less resources and processing power, meaning your results are delivered quicker and more effectively. Please don't use the CSV Editor if no actual data manipulation is required. Use the CSV Reader instead.
Please note that the CSV Reader and CSV Editor cannot be used interchangeably. A CSV instance created in the CSV Reader is not compatible with an instance created in the CSV Editor and vice versa. For example, a CSV instance ID created in the Editor is not valid if used in the Export CSV operation in the CSV Reader.
| Connector | When to use |
|---|---|
| CSV Editor | When heavy manipulation of, or adding to, the data within the CSV file itself is required. |
| CSV Reader | When read-only access is needed, particularly when querying very large CSV files, paginating through the results and exporting said results. |
Example scenarios for usageCopy
Some example scenarios for the CSV Editor include:
As a Look up table. Again, if only reading is required, then please use the CSV Reader instead.
If you have data to manipulate in the future - e.g. some 'contacts' have been input to your CSV with a 'registered date' field that is not yet available from the source you are pulling data from. So you store the CSV at account-level and run a scheduled trigger to check for the updated data and update the CSV when it is found.
As an alternative API service. If you don't have an API that is fit for purpose, then the CSV Editor could be used as a small scale, simple, API service.
To run a Custom Query
Temp vs Persistent CSVsCopy
By default, the operations 'Create CSV' and 'Create CSV from file' create a temporary CSV that is deleted after the current run of the workflow.
So you can only perform operations on this CSV within a single run of your workflow.
However, It is possible to export a CSV in order to make it available for use in another workflow. A common scenario for this is:
In your main workflow, you have done the initial work of pulling in data and creating a CSV
You now want to pass the CSV on to a second callable workflow in order to carry out some secondary processing, perhaps involving another third-party service
This 'modularized' way of working can help simplify your workflows and give you a clearer view of what you are working towards.
Please see the below section on persisting across workflows for details on this method.
Note, however, that it is not possible to permanently save information back into an exported CSV - you can only edit it and then use the finalized data to send to e.g. a third-party service.
If you wish to keep a CSV for repeated editing - over a period of, say, 4 weeks - you should store it at account level
Intro ExamplesCopy
After going through the intro examples please read on through the notes and examples on efficiency and workflow optimization!
Create an empty CSVCopy
Perhaps the most common usage of the CSV Editor is:
Create an empty CSV file
Pull records from a service
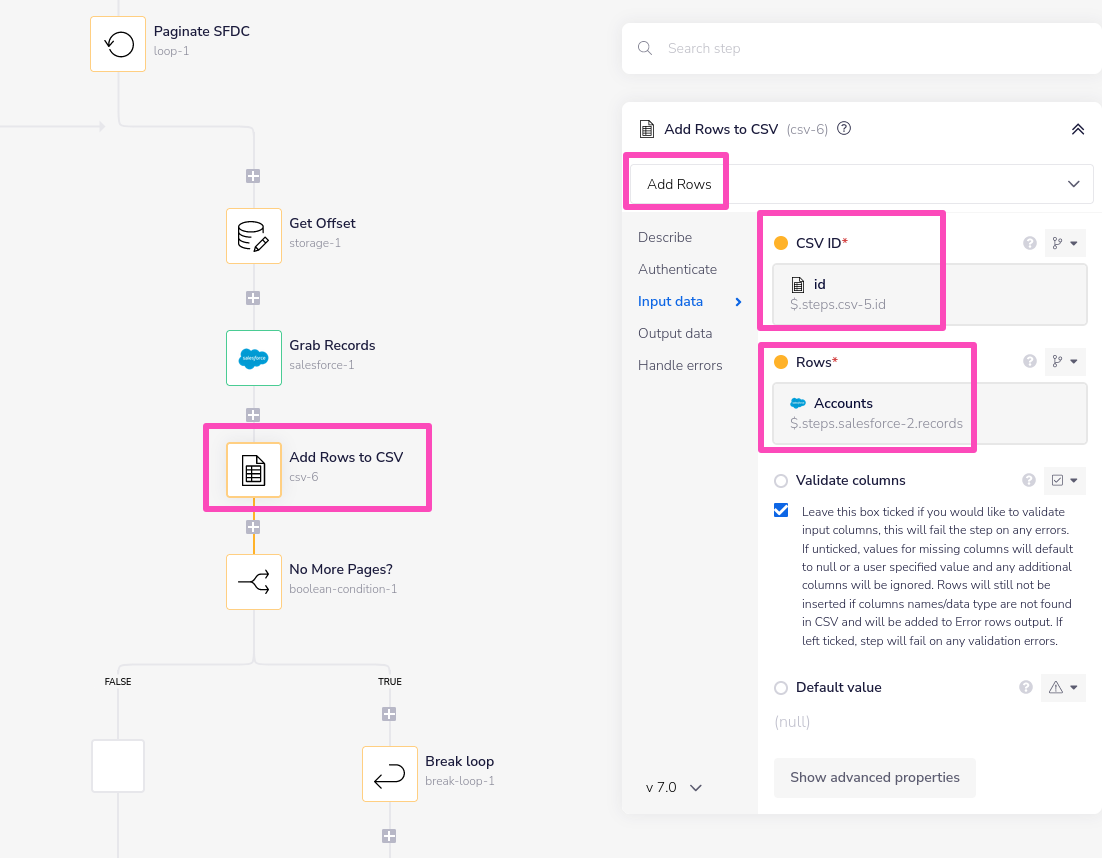
Add these records as rows to the created CSV - using the 'Add Row' or 'Add Rows' operations
When using the 'Create CSV' operation you must specify the number of columns and the names of the columns.
This can be done:
Manually by entering the columns directly in the 'Create CSV' operation
Dynamically by using the 'Create columns from object' operation to auto-create columns based on data returned from a service
The dynamic option is the more likely, and more 'correct' of the two, as it allows you to set up a CSV creation method which will respond automatically to any changes to the data coming in to your workflow.
Here we will give you a simple overview of how to create CSVs dynamically. Once you have read through this you can see the following templates for full detailed examples of creating dynamic CSVs in realistic scenarios:
Create a CSV file from JSON array
Generates a CSV file from a JSON list of objects then (optionally) sends the CSV via email
Extract Salesforce records and email as CSV
Paginates through any number of Salesforce records and emails the resulting CSV
The manual optionCopy
The following shows manually entering the number and names of the columns when using 'Create CSV':

And being sure to set the number of rows to 0, to make sure it is empty:

The 'Create CSV' operation will return a unique ID that needs to be used in all other steps in which we want to manipulate the CSV data:

Once the CSV is created you can add rows to it, by referencing the ID of the created CSV:

The dynamic optionCopy
The dynamic option can be used when you have received data from a particular service and you want to automatically create the correct columns for your CSV.
It allows you to set up a CSV creation method which will respond automatically to any changes to the data coming in to your workflow.
This can be done using the 'Generate columns from object' operation:
The following example shows generating the columns from the first object in a list of Salesforce records:

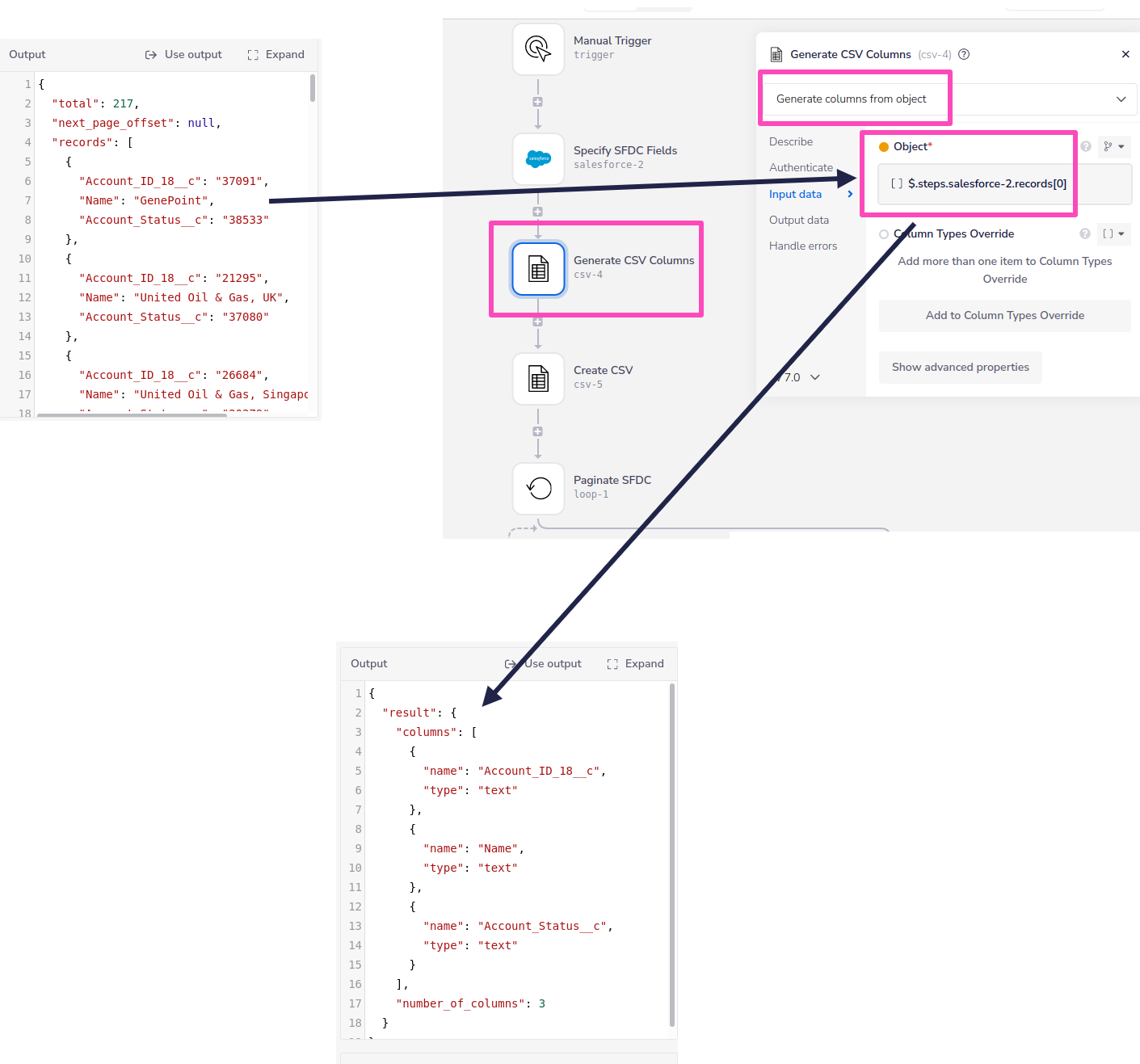
This can then be used to feed the column names and number of columns into a CSV Editor 'Create CSV' step (remembering to set number of rows as 0):


Any subsequent 'Add rows' operation will need to acess the CSV id using e.g. the $.steps.csv-5.id jsonpath:

Please see the following templates for full detailed examples of creating dynamic CSVs in realistic scenarios:
Create CSV from fileCopy
Create a temporary CSV file for use within the current workflow execution, from a pre-existing file.
Add the Google Drive Connector to the workflow and setup your authentication (see the Google Drive docs for more details). Set the operation to 'List files'.
Set the 'Filter by Folder' drop down option to your target and the 'Filter by name' to the file name you wish to download.


Add another Google Drive connector to our workflow and set the operation to 'Download Google file'. Use the connector-snake to set the 'File ID' to the ID from the previous Google Drive download step. The 'File type' should be set to 'CSV (first sheet only)'.
When the workflow is run, the output from the 'Download file' step will provide a URL to our downloaded file.


Add a CSV Editor step to your workflow and set the operation to 'Create CSV From File'. The pre-existing file must come from a URL reference point as the CSV Editor will require the URL of the file in order to bring it into the workflow. Use the connector snake to set the 'File URL' field to the URL output from our Download File step. If you now run the workflow your CSV file will be available to be manipulated in the output of the CSV Editor step.

Persisting across workflowsCopy
By default, the operations 'Create CSV' and 'Create CSV from file' create a temporary CSV that is deleted after the current run of the workflow.
You can perform operations on this CSV within a single run of your workflow.
If you wish to use your CSV in another workflow, you can pass the file url to a Callable Workflow.
Note, however, that it is not possible to permanently save information back into an exported CSV - you can only edit it and then use the finalized data to send to e.g. a third-party service.
If you wish to keep a CSV for repeated editing - over a period of, say, 4 weeks - you should store it at account level
The process for persisting a CSV is:
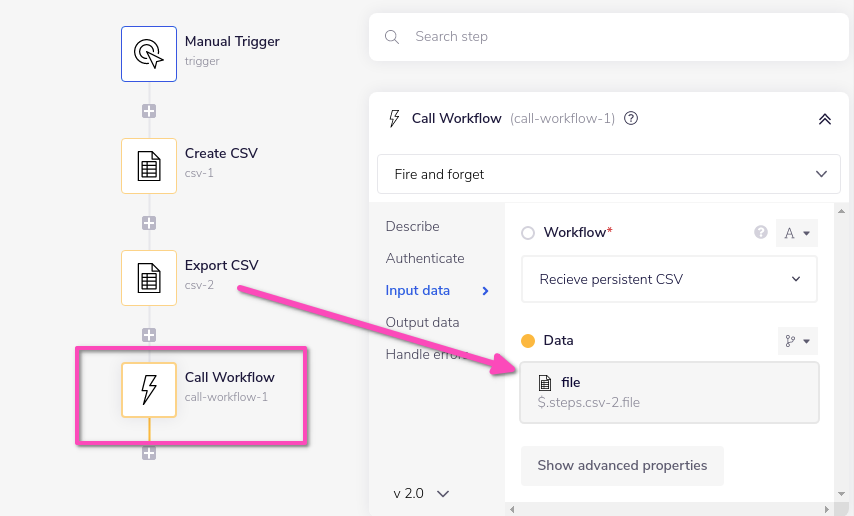
Use the Export CSV operation, by pulling in the id from a previous Create CSV step (using
$.steps.csv-2.filein this case):

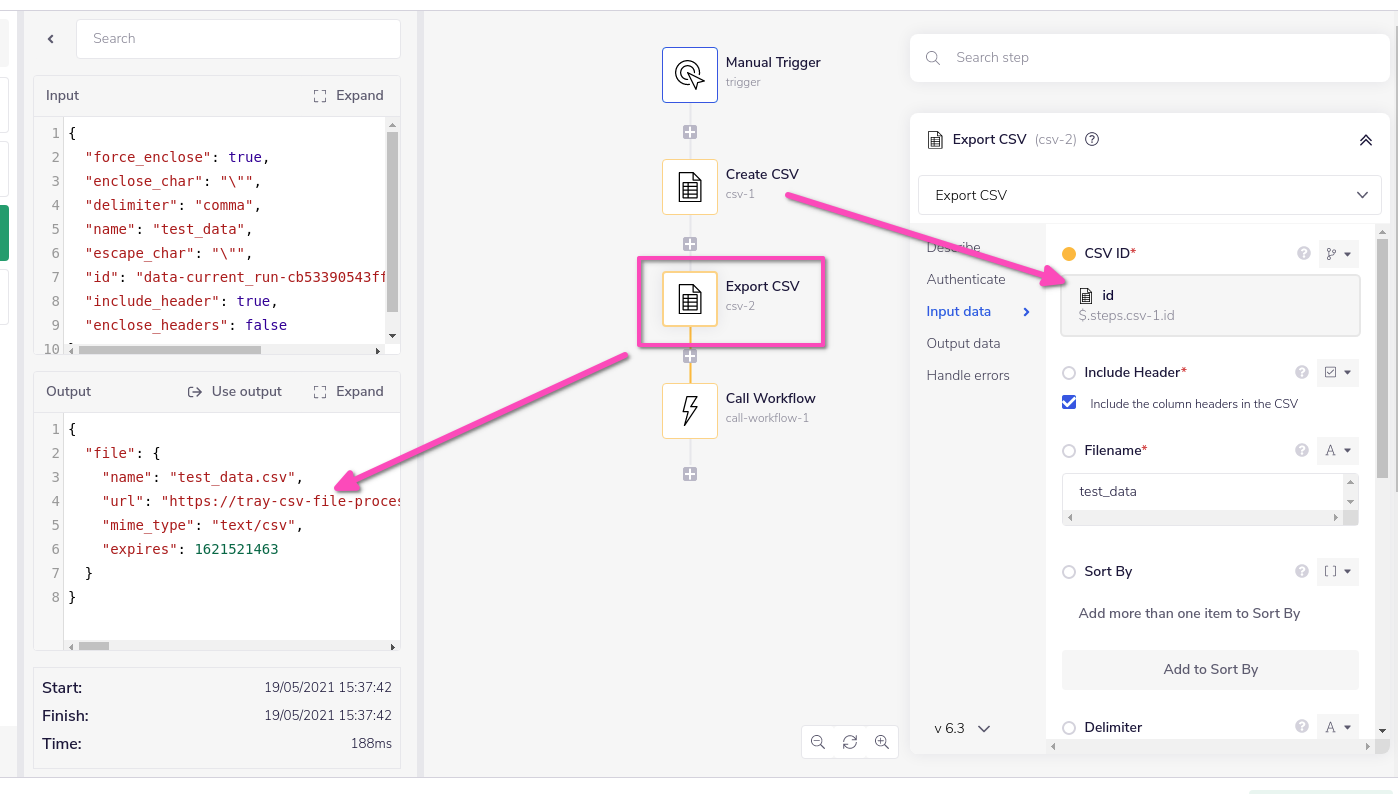
The resulting file is then passed in as Data in the Call workflow step:

Then in the workflow being called, you can recreate the CSV from the file url passed to the trigger (using
$.steps.trigger.url):


You are now free to build your secondary processing workflow!
Account level dataCopy
In terms of having multiple workflows access a single CSV, your needs will often be met by persisting a CSV, as per the method above.
However, there may be times when you need to store a CSV at account level for a period of time. For example, you may need to store a CSV which is available for editing by several manual- or scheduled-trigger workflows, before being finally processed and deleted.
The following workflows demonstrate a typical life-cycle for an account-level CSV:
Create the account-level CSVCopy


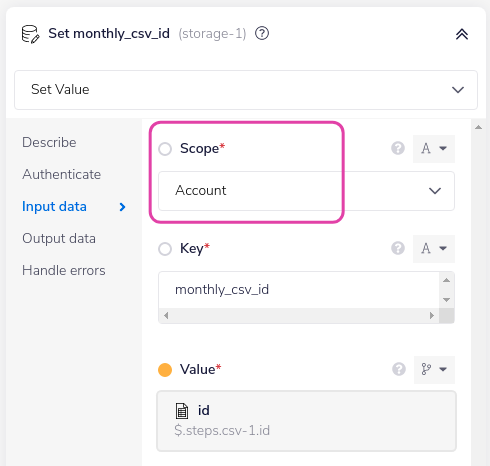
This workflow creates an account-level CSV from an email attachment:


And stores the id in account-level data storage:

Edit CSV with other workflowsCopy
Any number of workflows can then access the account-level CSV, such as this one which sanitizes the data - using 'Delete rows by filter' to delete any entries which do not contain an email address:


It gets the csv id from account-level data storage:


Then uses the id for the 'Delete rows by filter' operation:

Process and delete CSV at the end of the monthCopy

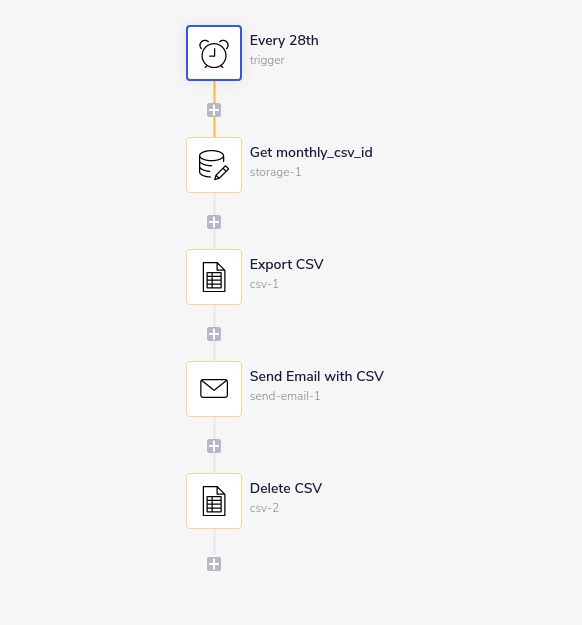
The final workflow in this example runs on a scheduled trigger.
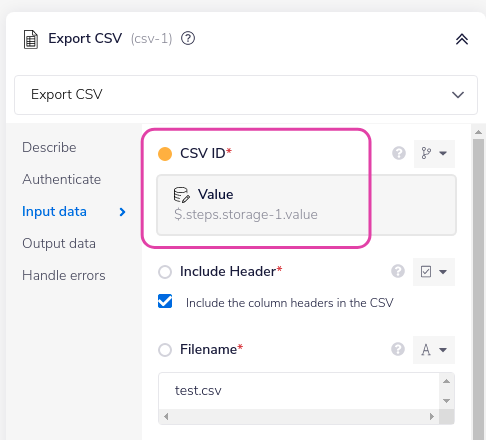
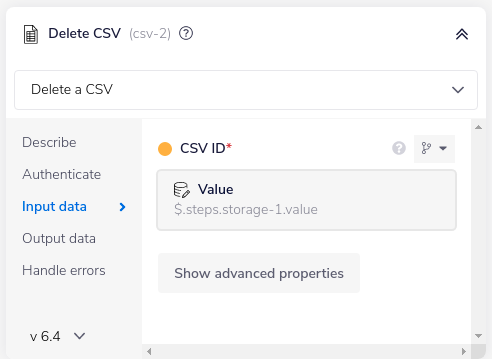
It gets the csv id from data storage again.
Then it exports the CSV to file:

Attaches the file to an email:

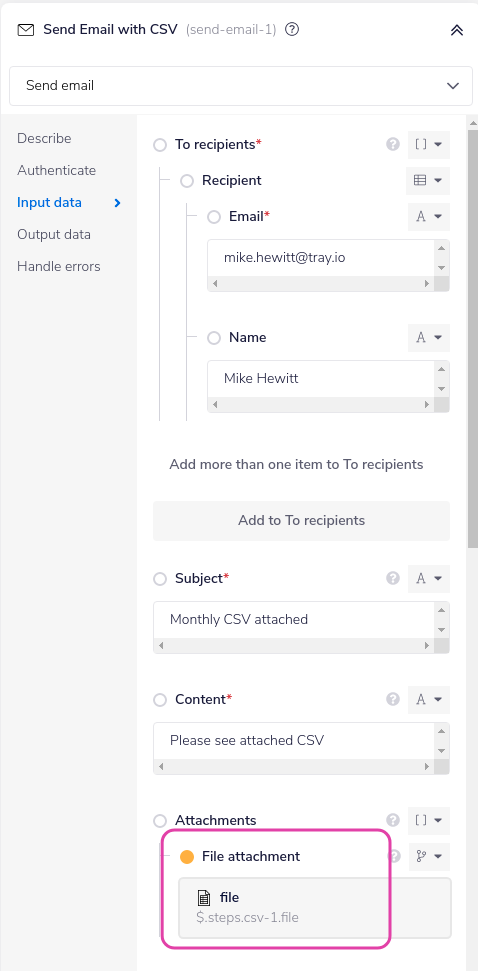
Then, finally, deletes the account-level CSV:

Parse text from CSVCopy
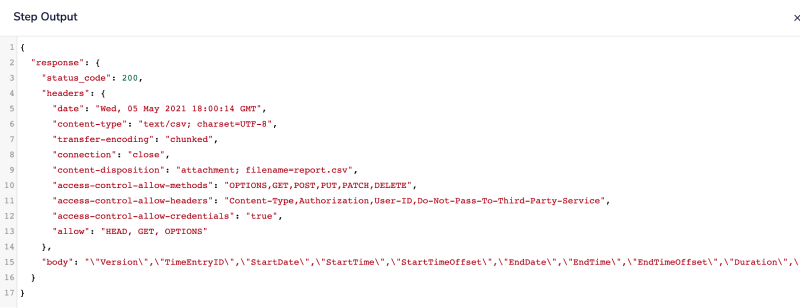
In order to handle raw CSV text, the CSV Editor has a 'Parse Text' operation which will convert raw text into a list of rows.
Often the incoming data will be in the format of the 'body' in the webhook Input panel below. Notice how the delmiter in the example uses a backslash \ to separate the raw data.

To simulate the use of raw CSV text in a workflow and to keep things simple, this example will use the Javascript (previously known as 'Script') connector in conjunction with the following mock data:
1,Malinde,Monier,mmonier0@netvibes.com,Female 2,Fiann,Ayling,fayling1@i2i.jp,Female 3,Jasmine,Schulze,jschulze2@sourceforge.net,Female 4,Clerkclaude,Tedman,ctedman3@ox.ac.uk,Male 5,Tina,Asey,tasey4@thetimes.co.uk,Female
Drop the Javascript connector into a workflow with a Manual trigger, and set a 'Variable' -> 'Name' for the mock data. Running the workflow should now return the mock data.


Drag a CSV Editor step into the workflow and set the operation to 'Parse Text'. Set the 'Delimiter' attribute to reflect the data you're using. In this instance our text is delimited by a comma
,.Running the workflow will parse the data and return a list of rows.




Update rows by filterCopy
The CSV Editor has operations which allow you to apply a filter to find specific row(s) and to then modify said rows that are returned.
As mentioned below in the note on running queries efficiently, setting up indices for your filters helps your workflow run faster as it means the workflow has less to search through.
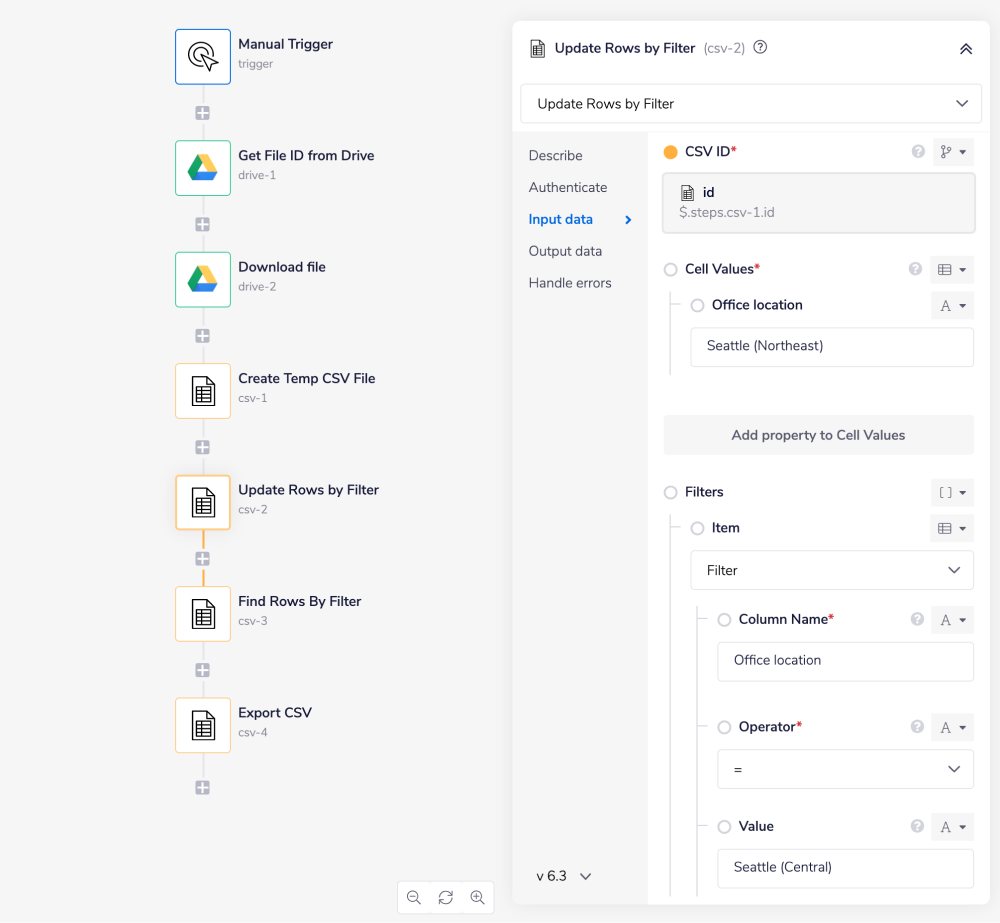
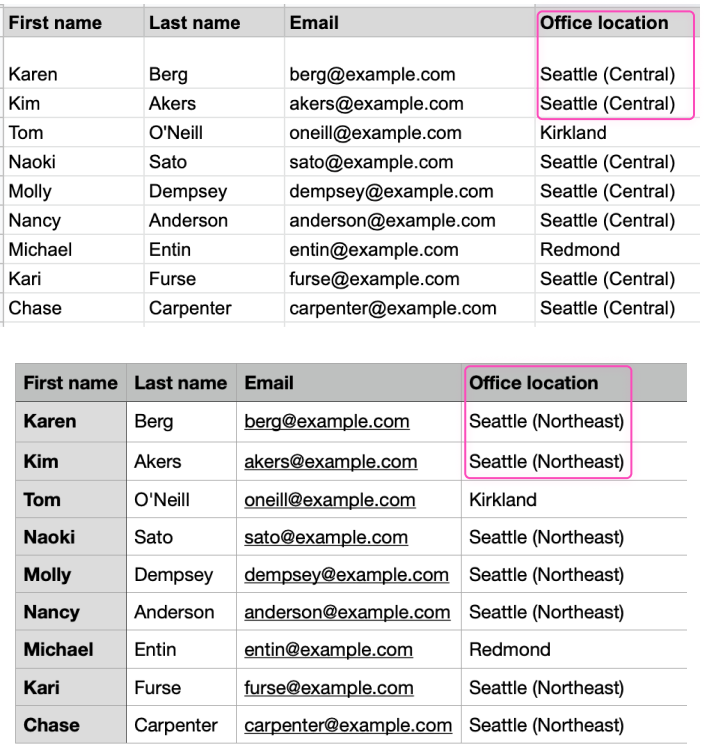
In this example we will search for all the rows where Office location is equal to Seattle (Central). Where this returns true, we will update the address to Seattle (Northeast).
This walk-through builds upon the previous example, Create CSV from file.
The key step here is Update Rows by Filter. In this example we set
Office locationin 'Cell Values' attribute and set it toSeattle (Northeast): A filter is added to find all entries whereOffice locationis currentlySeattle (Central):

Running the workflow now will update the targeted cells within the filtered rows. If the run is successful, an object will be given in the Output panel providing details of how many rows were updated.
As an extra step, you can use the 'Find Rows by Filter' operation and inspect the logs to see the updated cells / text in the output panel.



Efficiency and scalingCopy
Running queries efficientlyCopy
Workflows that use CSV Editor steps should be designed in a way that maximizes efficiency to avoid lengthy execution times. Below are some general points to help you optimize CSV Editor usage in your workflows.
Typical use cases that require at least some amount of optimization, are as follows (see our Example efficient workflows section for more details):
Loading in and paginating CSV data.
Retrieving data from an existing CSV.
Creating and adding (batching) rows to a CSV.
You will find the following tips useful in such scenarios:
Generally the number of requests to CSV Editor can be reduced by batching up rows. This increases overall efficiency for the workflow and the platform.
Certain operations require more resources than others For example, the 'Find row' operation uses more resources than the 'Find rows by filter' operation, as it has to calculate the location where the row was found.
When it is known that only one or two columns will be searched frequently, it is best to add these header names to the 'Column indices' field. This will significantly improve the speed of searches
Calling concurrent workflow executions against the same CSV ID should generally be avoided i.e. if you are using an account-level CSV make sure that multiple workflows (or parallel runs of one workflow) are not attempting to access the same CSV (this is relevant when you are workflow threading)
Querying a row valueCopy
Remember - if you only need to query data throughout your workflow, and do not need to edit it, please use the CSV Reader instead of the CSV Editor.
That said, if you wish to query a particular row value, we advise you to use the "Column indices" field option found within the "Create CSV from file" operation.
The row value will be found quicker, as it reduces the index processing time. So make sure you set up your table indices correctly.
This means the column headings and data types must be accurate.
Find Row vs Find Rows by FilterCopy
This can be confusing, as both operations can technically utilise a filter method. It is important to understand the difference so that you can use the best operation as per your use case.
Find Row returns the first row that matches the filter, and calculates which row number it found the data at. It can be used in conjunction with a filter, but should ideally only be used when there is just one result expected.
Find rows by Filter returns all of the rows in question which match the filter parameters, but doesn't return the row number associated with them. This operation should be used when searching for multiple matches, or if the row number itself is not relevant to the results.
If multiple rows must be retrieved (one at a time or in batches, the latter being optimal) then it is strongly recommended to use 'Find rows by filter' operation. They should be handled with an index specified in the Column indices creation input.
MinimizeCopy
Unless you specifically need to store data for later retrieval, store CSVs at "current run" as opposed to "account" scope.
Results will be delivered quicker and more effectively this way.
Essentially you should grab, manipulate, use and throw away your CSV data per workflow run.
We also advise that you keep the number of table rows and columns to a minimum.
AccuracyCopy
NamingCopy
Try and be specific (e.g. specify column names in the properties panel, even if they’re also in the CSV and should be picked up automatically)
Naming column headings accurately also makes your workflows easier to understand and therefore easier to manipulate.
Data typesCopy
Please make sure that the Data Type for each column corresponds with that expected by any third party service you may be transferring data to.
There are a lot of different formats and requirements for CSV files: delimiter, quotes, etc. Research the API documentation of the third-party service you are working with for example data requests and for further clarification.
If you accidentally mix data types during manipulation (e.g. use the CSV Editor to add a string into a number field in a third-party service) the service API's response may not be reliable. In some cases the attempt will just fail while in others it might succeed but produce unexpected results.
Technical limitsCopy
The CSV Editor is subject to the following technical limits:
| Case | Limit | Notes |
|---|---|---|
| Data that can be extracted from, or sent to, the CSV Editor in a single call | 1GB | more is likely to cause issues |
| File size limit when importing to the CSV Editor | 1GB | |
| Max payload between steps | 1 MB | as per between standard connectors in the builder |
| When I export my created CSV I get a download url | ||
| How long is the download URL active for? | 6 hours | as per standard link persistence policy |
Example efficient workflowsCopy
Handling huge data files (>100MB/ 1 million+ use case dependent), requires special workflow considerations in order to make sure the process is optimized.
Retrieving data effectively can cut down on the number of API calls necessary, reduce the feedback loop and run your workflow overall more efficiently.
It is important to retrieve data succinctly and make sure you import and paginate effectively. If you wish to add numerous rows to your CSV file then batching requests helps speed up the process.
Below are three workflow examples that each highlight one of the efficiency points mentioned above and utilise a particular CSV Editor operation in order to help highlight this.
Searching CSV dataCopy
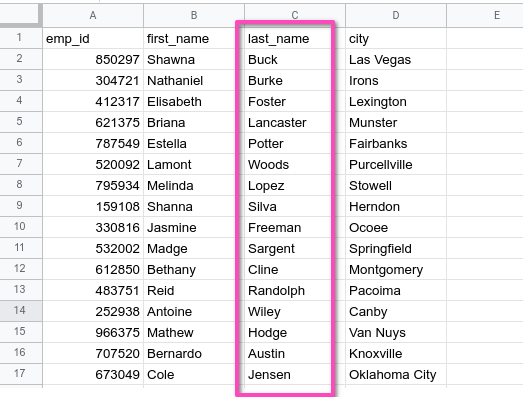
It is strongly recommended to add a Column Index when creating the CSV file that will be queried. Instead of querying the whole file, the CSV Editor need only check the column referenced.
To illustrate this we can look at the following table, where we know that the last_name column will be the primary means of searching for employees within the CSV:

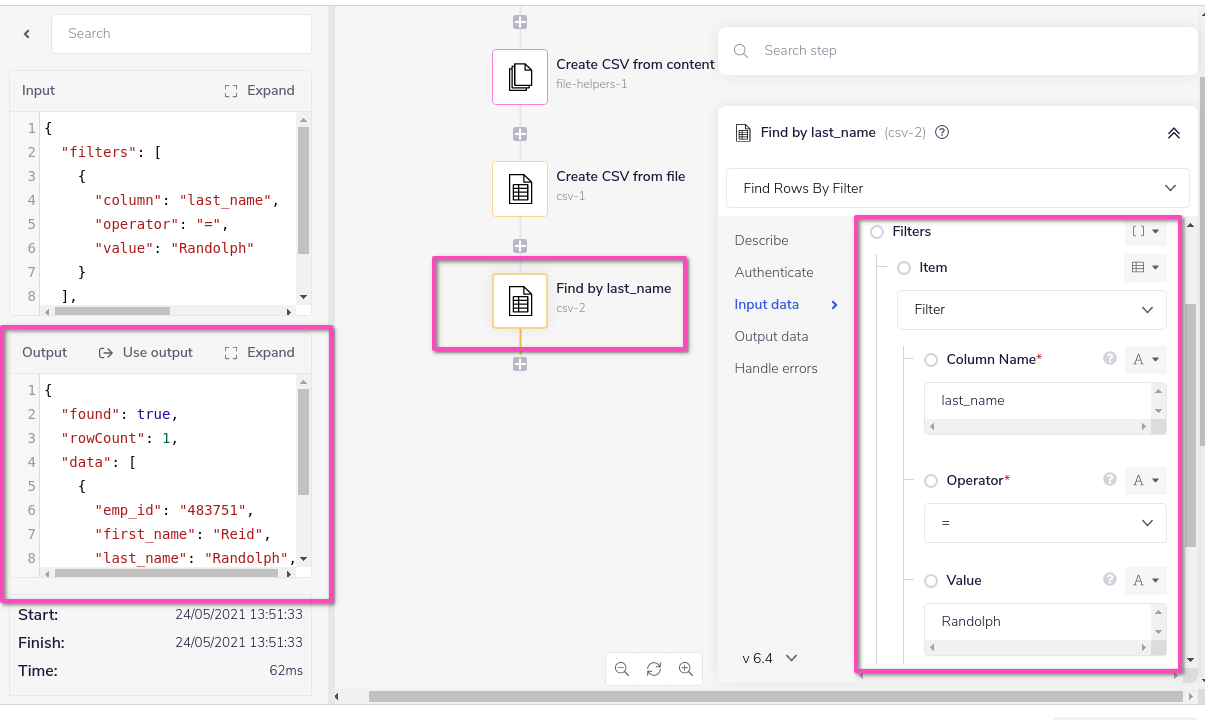
This can be set up by specifying a column index when you are creating a CSV:


The 'Create CSV From File' operation does not require 'Column Indices' fields to be set but by doing so it cuts down the workload that the CSV Editor needs to process.
The 'Find Rows By Filter' operation returns the rows in question according to the parameters set in the 'Filters' fields. Matching the filter with the 'Column Indices' fields from earlier accelerates workflow returns by reducing the overhead.

Batch data from a CSV to a serviceCopy
When handling large amounts of rows or data in a CSV file, it is necessary to create a 'pagination' system. The point of it is to break the results down into manageable chunks (of e.g. 100 records each). This way the workflow load is handled more effectively.
The method below is particularly useful for transferring data from one service to another when the file size is too large for a single run.
Note that this method makes use of config data to set the size of each batch being paginated:

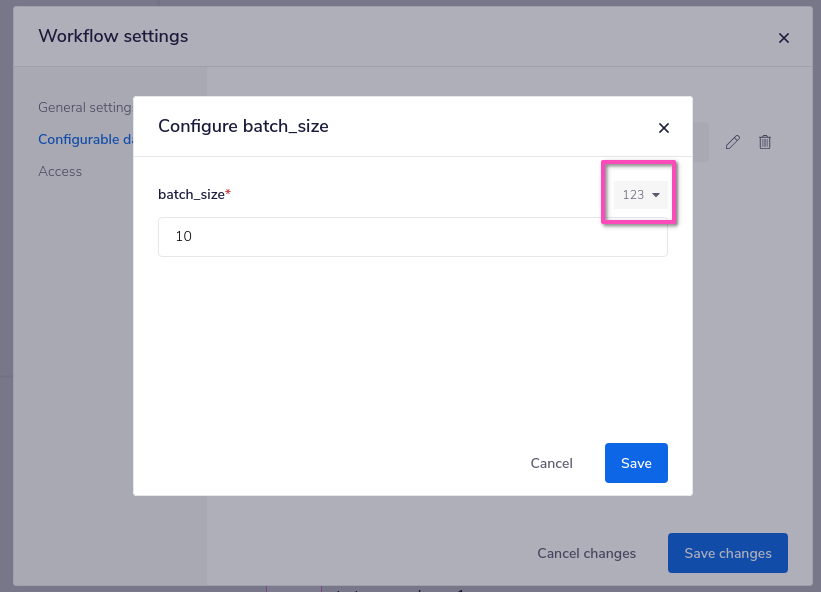
Note that it must be set as an integer - not a string!
This is a best practice for a variable that you want to use in repeated steps throught your workflow, and means it is easy to adjust if necessary.
For simplicity and demo purposes we have set the batch size to 10, but in reality, you can use large batches of 100, 1000 etc. Click here to download an export (right-click and save) of the following workflow to test and run yourself:

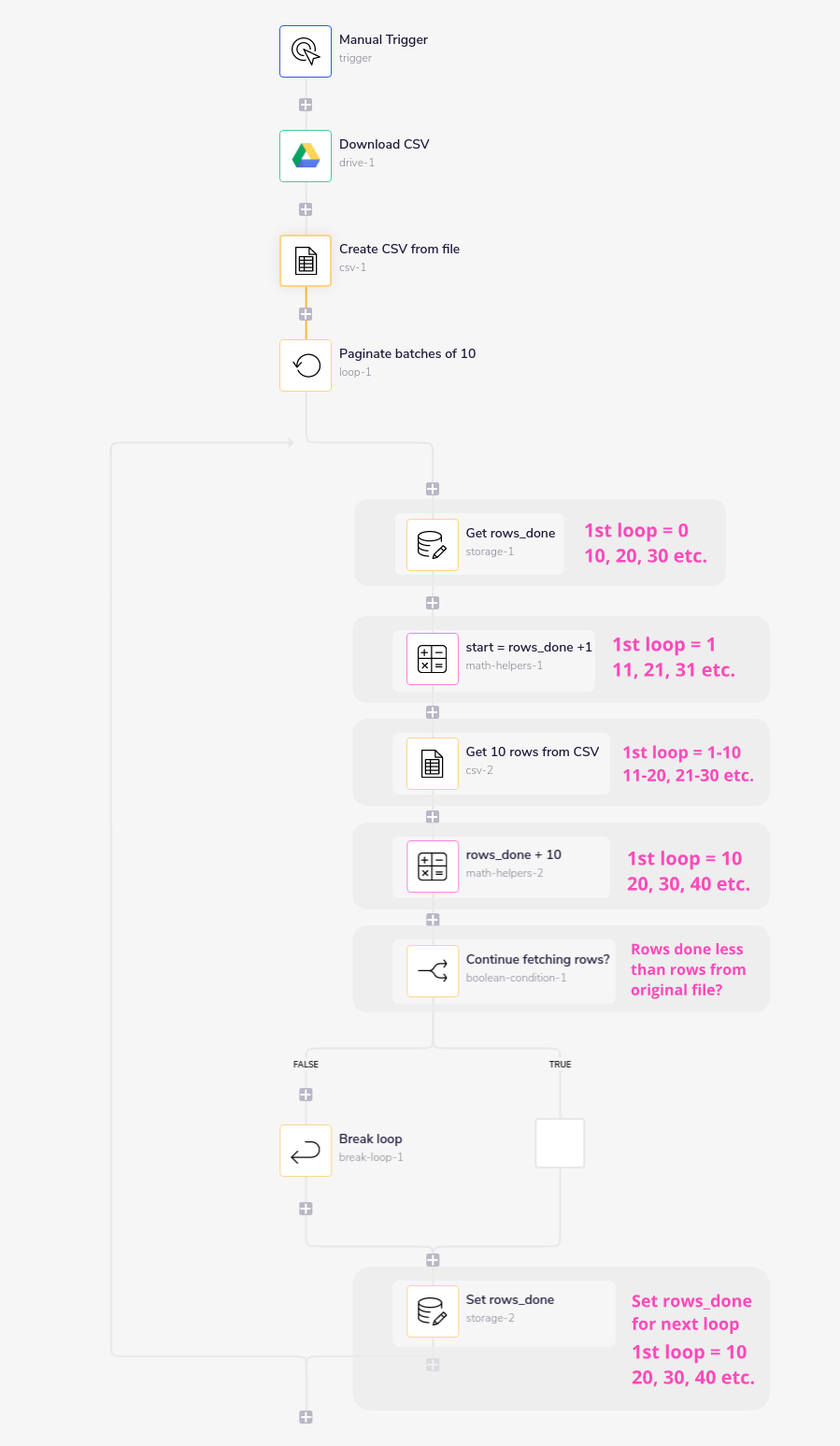
1 - Paginate batches of 10 is a loop connector set to 'loop forever'

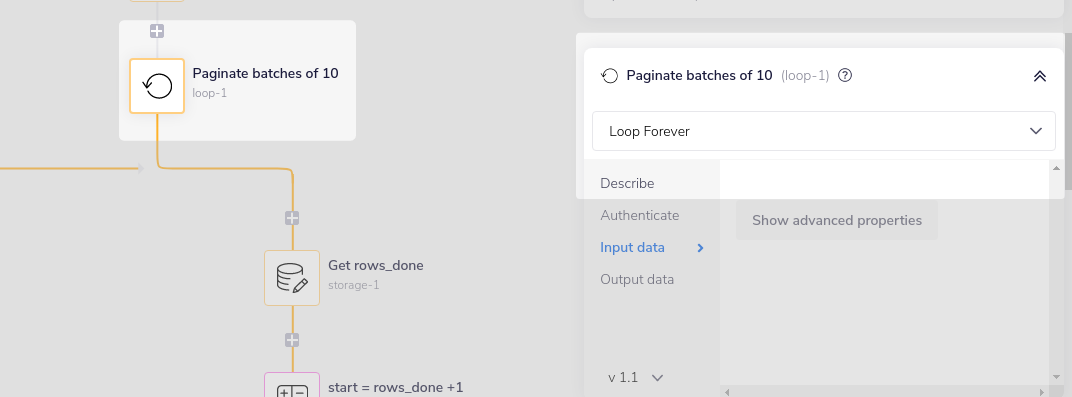
2 - Get rows_done gets the rows_done at the start of each loop, defaulting to 0 on the first loop:

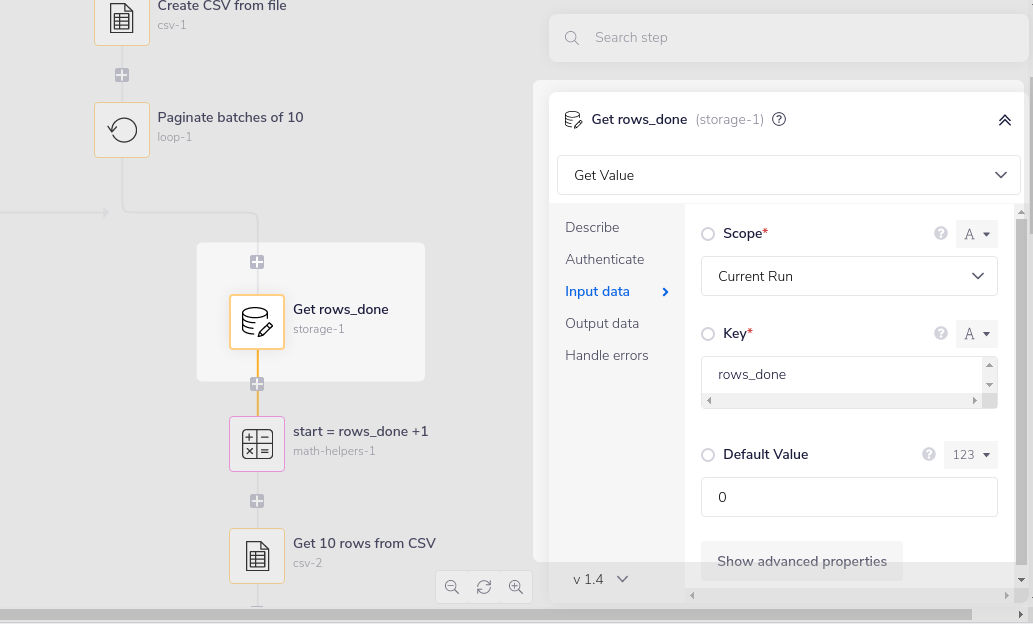
3 - start = rows_done +1 sets the row to start on for each loop (1, 11, 21, 31 etc.) by adding 1 to rows_done:


4 - Get 10 rows from CSV grabs the id from the first CSV step, feeds in the start row and the batch size (from config data):


5 - rows_done + 10 adds the batch size onto rows_done to calculate the new total for rows_done

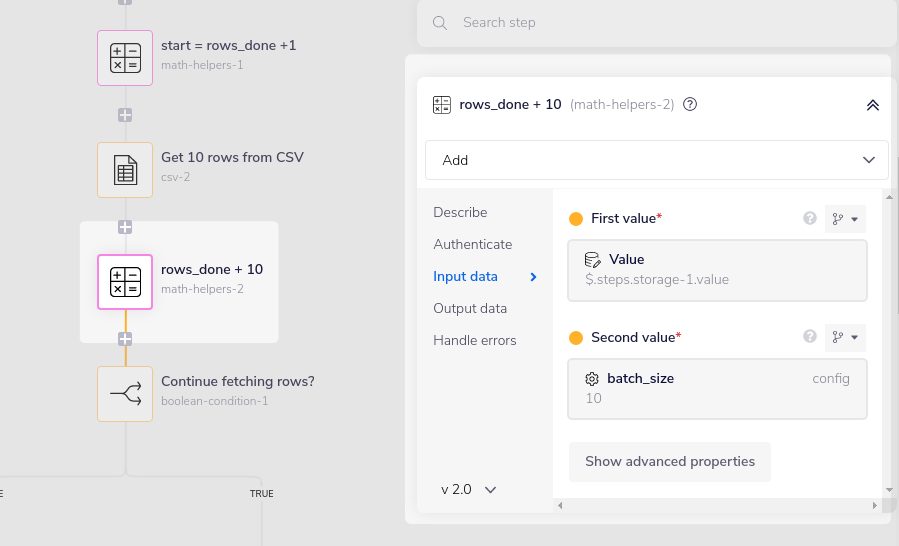
6 - Continue fetching rows checks if the new rows done total is still less than the total rows from the original CSV file:

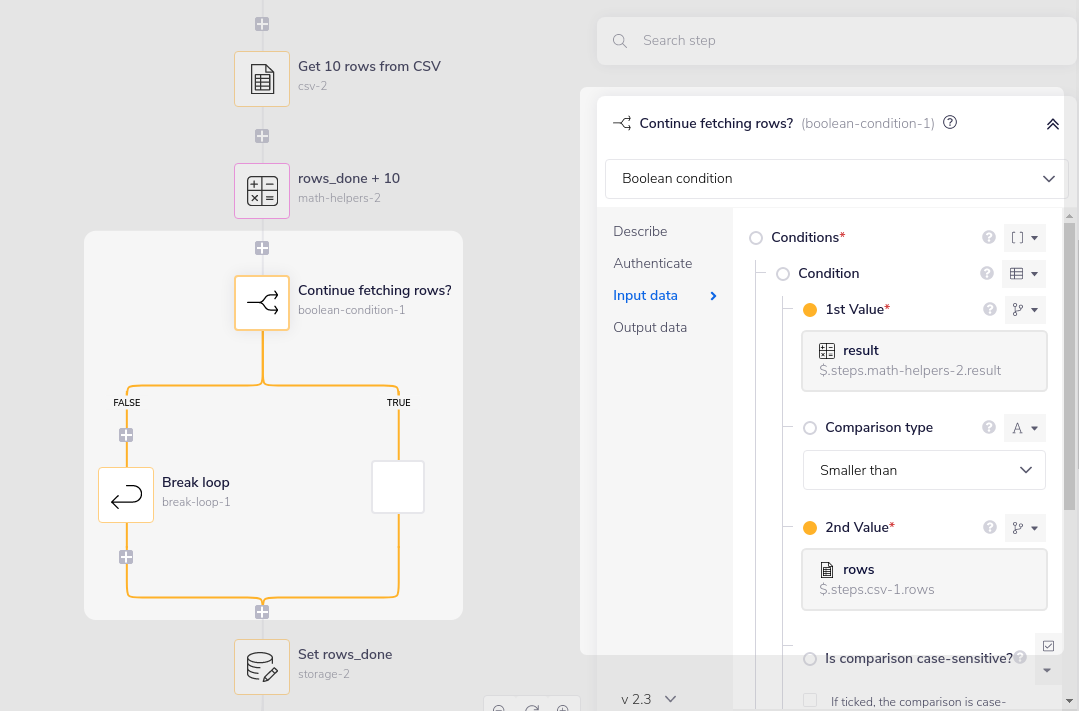
7 - Set rows_done sets the new rows_done total for the next loop to retrieve:


Batch data from a service to a CSVCopy
When pulling data from a third-party service to input to a CSV, it is important to divide lengthy lists of records into smaller batches.
In this way you can process e.g. 10 batches of 2000 rows instead of trying to process 20,000 records at once.
Most services will actually only allow you to pull a certain amount of records in one call - e.g. Salesforce has a limit of 2000 per call, and it will return a 'next_page_offset' so that you can then pick up from 2001, 4001 etc.
While batching is important what is most important for optimization is to not try and run too many concurrent executions against the same table as it could cause locking issues.
So if you have created an account-level CSV, you should make sure that you do not have multiple workflows or threaded executions of the same workflow attempting to write to the CSV at the same time.
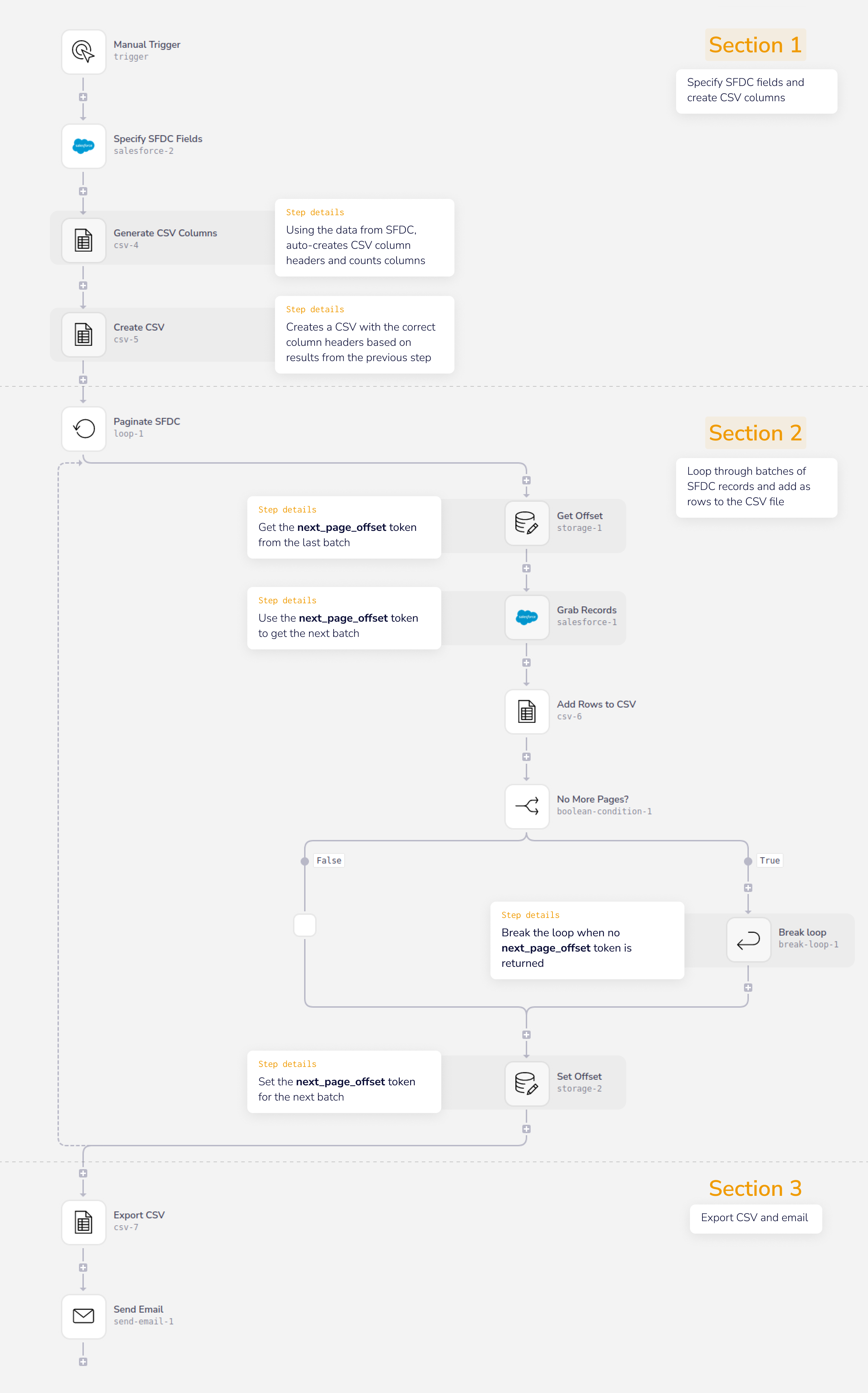
The following workflow is taken from our template 'Paginate through Salesforce Records and Email Resulting CSV' and it demonstrates setting up a pagination system:
Extract Salesforce records and email as CSV
Paginates through any number of Salesforce records and emails the resulting CSV
Note that it makes use of the dynamic method of creating CSV columns which will respond automatically to any changes to the data coming in to your workflow.