Workflow threads
When dealing with large amounts of data, workflow threading is a technique which can greatly help manage the efficiency and reliability of your workflows.
Threading basically involves dividing your data into batches to send them to a callable workflow for processing, and setting up a system to wait until the number of threads finished is equal to the number of threads started, before continuing to the next stage in your workflow.
This massively increases the efficiency of your data processing, as each batch will be processed in a parallel 'thread', rather than waiting for each one to finish.
This page will take you through how to set up workflow threads, including:
Using account-level data storage and the 'atomic increment' operation to set up a system which counts the number of threads running and identifies when they are all complete
Using 'environment variables' to pull the main workflow url as an identifier for the account-level data
Monitoring and taking action if any threads are taking too long to complete
Multiple threads single list exampleCopy
To demonstrate this we can look at a workflow which is pulling batches of records to be processed and sending them to a second workflow.
Note that this workflow could be manually triggered as and when you need to use it, or it could use a scheduled trigger.
This example assumes that overloading data storage is not a concern and so all the threads are feeding into a single list, which is then retrieved at the end of the main workflow.
You can download the two workflows involved to import and test yourself:
The processing single list workflow The explanation below will take you through the main points involved in these workflows, but they will not go through every single step! Please explore, test and analyse the above workflows for full details.
The main workflowCopy
The main workflow looks like this:

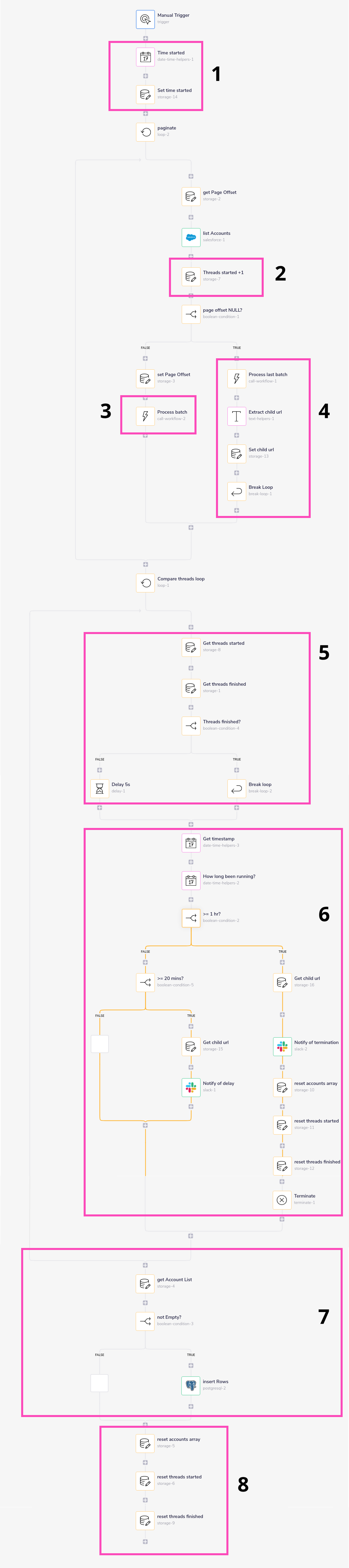
The numbered sections are explained as follows:
Make sure the list is reset to an empty array, while the thread counts are reset to 0.
Otherwise you will have a data type mismatch the next time the workflow runs!
The processing workflowCopy
The complete processing workflow looks like this:


The steps involved are:
Important notesCopy
Using a scheduled triggerCopy
When polling with a scheduled trigger, it is very important to make sure that a run of the workflow is allowed to complete before any more runs are triggered. To do this first click on Advanced Properties and then tick the box as shown:

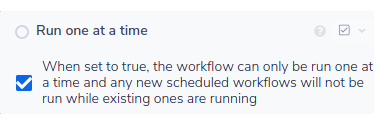
Your schedule should also be set so that you allow plenty of time for runs to complete. In a case where 3 attempts at starting a run are made while one is still completing, these runs are missed. They are not added to a queue.
Note: any data processing steps (working with a messages list, uploading to airtable etc.) in this example are given for demonstration purposes only. The technique of threading is applicable in multiple scenarios and with many different connectors.
Clearing account-level dataCopy
When testing, it is helpful to set a separate manually-triggered workflow which clears account level data as explained here.
This means you can easily reset your data if your workflow errors out.