


Enterprise software leader syncs 9 million records across production database and reporting tables
Run reporting from an overloaded, untouchable data server
A longtime computing leader sells a huge variety of products to enterprise customers across the globe. To track sales cycles across its teams, it uses a variety of different instances of customer relationship management (CRM) tools, including Salesforce and the on-premise solution SugarCRM. The company continues to have a robust and diverse product offering sold by numerous sales teams across the organization, which, in turn, generates a huge number of sales opportunities for the company to track.
Of course, the mission of the company’s business operations team wasn’t simply to maintain a huge database to house its millions of sales opportunity transaction logs. The company also needed to run reporting on those logs to provide visibility into its sales funnel for the purposes of budgeting and forecasting, as well as to gauge the technical health of its transaction logging process.
To address the issue, the business operations team started by attempting to run a daily snapshot report, which was slow going, given the server’s already-maxed-out memory levels. “Since the system was relatively fragile, we would pull only 2,500 records at a time, so we ended up with many batches to go through, taking a lot of time to backfill,” one team member explains. Development on the issue, taken together with the ongoing need to run daily reports, totaled eight hours of work every day.
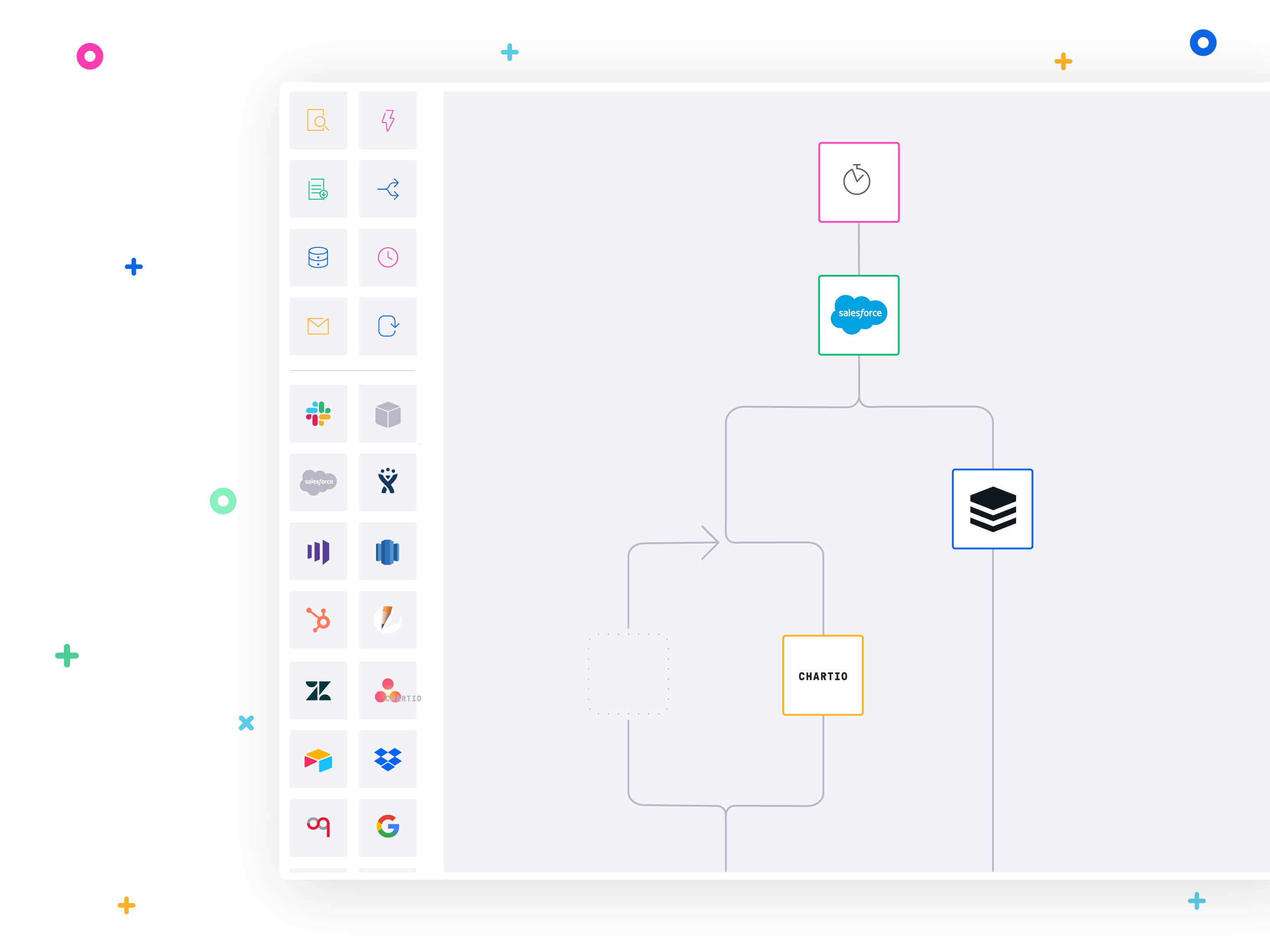
The Tray Platform syncs opportunity data in parallel
That’s when the team recalled its previous use of the powerful, flexible Tray Platform to build sophisticated, automated workflows to handle important business tasks such as custom lead scoring and syncing multiple CRM instances across numerous business units, even flowing data between a cloud-based CRM and an on-prem CRM.
Partnering with Tray.io’s customer success team, the team was able to rapidly build out automated workflows to set up parallel reporting tables. These workflows combined its database and CRM instances with the Tray Platform’s custom logic helpers to transform and route its data, including scheduling helpers to set reports to run at specific day-and-time intervals, Boolean logic conditionals to trigger branching follow-up steps, and functionality to store stepwise batches, paginate lists, and loop data processing, row-by-row, for each of its millions of opportunity transaction records. All told, the process of building out these workflows took only a few days.
8-hour reporting down to 5 minutes, removing production burden
With these workflows in place, the team has been able to exponentially increase its reporting speed, going from 2,500 records in a day to 2 million records in an hour. “We didn’t want to continue to store this huge amount of data on the production server,” the team explains.
“We wanted our data to be clean and stable, so with this replica, we now have historical data on record. We can go back several months and troubleshoot - see the reasons that this or that process broke, and check the interactions.”
The team adds, “We’d previously had eight people doing 40 hours a week on this. This was a process that used to involve taking days to build things out in SQL, then spending hours in Excel. We got that down to five minutes a day, and it’s fantastic.” The team also reports that executive satisfaction regarding this important sales data is much higher now that the Tray Platform’s workflows provide more-responsive reporting and greater visibility.
We were struggling with pulling 9M+ records out of our production environment, which took an 8-person team 40 hours a week. We got that down to 5 minutes a day, and it’s fantastic.


