Intro to the lead processing pipeline on the Tray platform


Niels Fogt
Senior Director of Automation Solutions
Get a hands on look at how B2B lead management can be handled using this workflow on the Tray platform
In our previous post, we laid out the case for building your RevOps processes on a low-code automation platform (like the Tray Platform). We ended with a high-level introduction to the framework we use to orchestrate the B2B lead lifecycle, calling out the primary workflow of this framework the “lead processing pipeline.”
Today we’ll be exploring some of the architectural concepts underpinning the framework and finish by taking a closer look at how things function in the pipeline workflow.
Our design objectives
Prior to rethinking our lead processing, we ran a hybrid model where we’d asynchronously do some jobs on the Tray Platform and others with external systems (primarily Marketo or Salesforce). The shortcomings of our approach helped drive the decisions we made and led to the following objectives for our new system:
Every lead should go through the same process, regardless of source (e.g. chat, web form, third-party ad vendor, list upload)
We will no longer rely on native integrations to create leads
We manage all phases of initial lead processing synchronously
We narrowly focus each workflow in our process on a single job to be done
We will highly standardize data in our workflows
My instincts tell me some of these objectives are likely obvious to those in RevOps, while others may be a bit specific to the approach of using a tool like the Tray Platform. Either way, read on and the reasoning behind each should become more clear as we dive deeper into how things work.
CRM as the hub of lead creation
Given CRM tends to be the source of truth, it’s common for vendors to offer native CRM integrations to create and synchronize records between them. Herein lies the most pernicious problem facing sales and marketing ops teams: Troubleshooting overhead.
RevOps teams spend hours upon hours trying to sift through the proverbial haystack as stakeholders call out issues, like duplicate leads or data being overwritten unintentionally. With N number of systems creating leads and writing data, it can be a bit like playing whack-a-mole when trying to figure out which system is doing what and when.
We decided we’ll no longer let any bespoke system create leads first (e.g. Marketo → Salesforce). Instead, all leads are first created in CRM, then native integrations sync data from there. If we have an issue, we simply search the Tray platform logs and see exactly what happened, making a quick fix if necessary.
This approach has made monitoring and troubleshooting lead processing issues much easier. Additionally, our stakeholders are happy because they can use the systems they want to generate leads without having to worry about what headaches that system’s native sync (or lack thereof) may drop in our lap.
The level of predictability and visibility is honestly one of the most under-appreciated aspects to using a tool like the Tray Platform. The ability to understand exactly what is happening is a godsend for ops teams trying to solve systematic issues, but I digress.
Lead Management “jobs to be done” via “RevOps Micro-services"
If you’ll recall from our first post, the pipeline workflow is built around the lead processing jobs to be done:
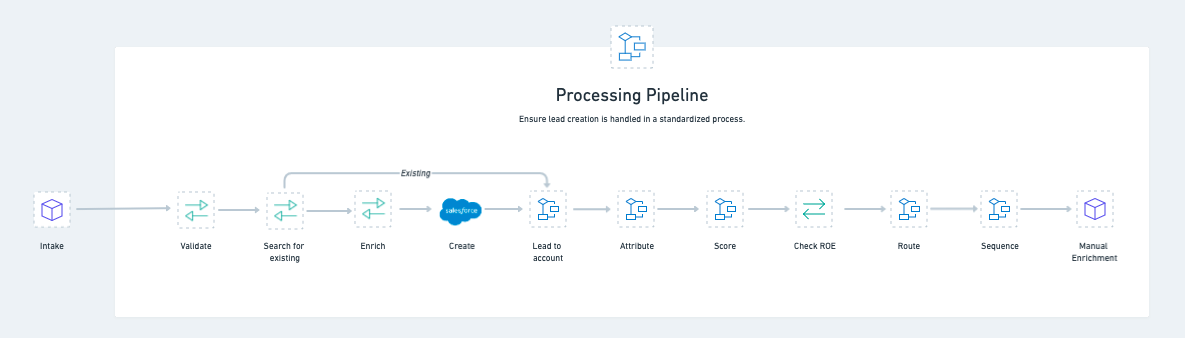
When we build our workflows, we try to focus on the most narrow function (or job) that workflow should support. How would one put this in place with the Tray Platform? The following is the most important concept when building solutions like the lead management framework. If you take nothing else away from this post, this would be the thing to master.
The big idea here is that each of our core lead management jobs are separate workflows, built independently of each other. In the development world, you might call them “microservices”, which are, by design:
Highly maintainable and testable
Loosely coupled
Independently deployable
Organized around business capabilities
The symbols shown on the diagram above represent a single Tray Platform workflow (aka the “microservice”) that maps to a job in our lead management process. We carry out our mapping by making each workflow “callable” — which means we can use them independently from any other workflow.
Here are a few real-world examples where our demand gen team has reused our attribution workflow to trigger gifts to prospects using Sendoso’s Salesforce integration:
Whenever a prospect books a call with an AE via Chili Piper, we listen for this via Tray webhook, lookup the prospect by email in Salesforce, check if they’re an “A” lead, and add them to a Salesforce campaign using our attribution workflow, which triggers a Sendoso e-gift card for the coffee.
Whenever an AE runs the
/egiftSlack command, a bot offers them a set of predefined e-gift options they can send to a prospect. They click a button with a prompt for the prospect’s email via a Slack modal. A workflow then listens for the modal submission, looks up the prospect via email, and if our business rules allow (e.g. this prospect is not in a banned country), it adds them to the appropriate SFDC campaign for the selected e-gift using our attribution workflow once again.
The primary job of the attribution workflow is placing a lead or contact into a Salesforce Campaign Membership, nothing more. There’s logic that deals with things like ensuring an end user provides a valid membership status, last-touch attribution for the lead/contact is recorded, etc. Once we write our logic, we never have to deal with it again and can use it over and over for different use cases!
Let’s take a moment to see callable workflows in action. I’m going to show you a callable workflow we use in each of the above examples: “Search for existing prospect by email.”
We love callable workflows because they check a number of boxes that make building process automation better:
Narrow focus means easy maintenance and troubleshooting
Reusability means we can accommodate new use cases more quickly
They improve standardization as data structures can be broadly applied
Speaking of that last point, here’s our next important architectural construct: standardized data objects.
Keeping it Object-ive
When using a network of callable workflows to orchestrate processes, it’s important to find ways to make it easy for them to “talk” to one another. The standard language workflows (and most APIs) use is JSON, where you have “objects” that describe the data they process.
You can think of these like you would objects in a CRM, like Salesforce. Here are the objects we use in many of our RevOps workflows:
Person - A lead or contact from our CRM
Company - An organization associated with the lead or contact
Owner - The SDR, AE, or AM that owns the person in our CRM
Attribution - The properties of their inbound inquiry which we use for understanding marketing ROI
If you're interested, you can see an example JSON structure here.
Using a defined data structure is yet another way we ensure our processes are easier to maintain and extend for those working on them.
Our objects are agnostic of any tool in our stack. For example, we have a property in our attribution object called offer_type which refers to the type of offer (duh) the prospect inbounded on (e.g. Demo - Recorded, Demo - 1:1, Webinar, etc.). That same property is a custom property on a campaign member object in Salesforce that reads offer_type__c.
Having objects that are standardized and system agnostic makes it easier to make changes over time. If we decide in the future to add or change a vendor, we simply “map” their object/property conventions to ours, without heavy refactoring of the workflows that underpin our processes.
So, how do you execute something like this? There are a few options. For example, you can use our data mapper connector. However, did I mention how much we love callable workflows yet?
We decided to build our own callable workflow to which we can pass an object from any given system (think Salesforce lead), and it "transforms" that object instantly into the structure we outlined above.
Object transformation is an advanced concept and you don’t have to start here, but it’s worth understanding as you grow your portfolio of workflows and use them like LEGO bricks to serve more and more use cases across the revenue organization.
I’ve recorded the following video to show how this works in practice (maybe you can tell I’m pretty geeked out on this workflow?).
The processing pipeline: Show me the money!
All right, so we’ve spent quite a bit of time working through the “why” of our approach and some on explaining the “how.” Now I want to show you how the primary workflow that is the workhorse of the lead management framework works.
I’m going to stay mostly at the surface level, but our next posts will dive in even deeper into each workflow so you can see exactly how they function.
Thank you again for reading these rather lengthy posts, I hope you find them valuable and I'd love to see you next time as we see just how deep the rabbit hole goes.
Next post up: Open Source RevOps: The first steps of the lead processing pipeline
Reminder that you can watch a demo of the Tray platform here and find me on LinkedIn if you wanna talk shop.
Finally, if you're a Tray customer and wish to talk live about any of this, you can find me in the #revops channel of our customer Slack space or can ask your Account Manager to broker an introduction :)