
AWS Redshift 1.4
Amazon Redshift is a fully managed, petabyte-scale data warehouse service.
OverviewCopy
The Redshift connector allows you to query your Redshift database directly within tray.io, without having to worry about data pipelines or servers.
Connecting to your Redshift instanceCopy
To allow Tray.io to connect to your Redshift database, you'll need to either make your database publicly accessible or you can white list ALL the Tray public IP addresses based on your region.
Refer to the Tray public IPs document for complete list of the Tray public IP addresses.
Note: be sure to make it so that your Redshift database is only accessible with a strong username and password combination when white listing these IP addresses.
To do this:
Open up the "Security" section of your Redhift AWS. Open the "default" security group.


Click "Add Connection Type"


Add a new "Connection Type", using the "CIDR/IP" connection type, and one of the above IP addresses as the IP address to authorize.


AuthenticationCopy
Assuming that you already have a Redshift cluster set up, and have configured the access settings mentioned above correctly, we can proceed with the authentication process.
When using the Redshift connector, the first thing you will need to do is go to your Tray.io account page, and select the workflow you wish to work on. Once in the workflow builder itself, search and drag the Redshift connector from the connectors panel (on the left hand side) onto your workflow.
With the new Redshift connector step highlighted, in the properties panel on the right, click on the Authenticate tab and 'Add new authentication' (located under the 'Authentication' field).

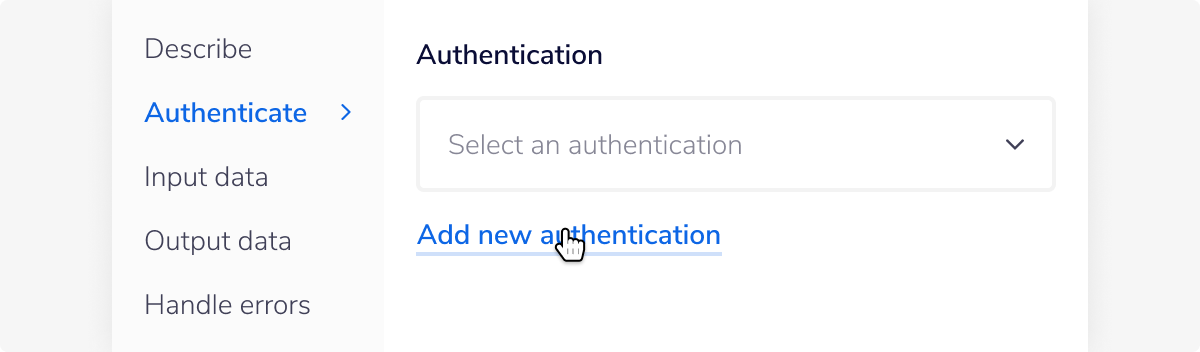
This will result in a Tray.io authentication pop-up window. The first page will ask you to name your authentication, and state which type of authentication you wish to create ('Personal' or 'Organisational').
As you can see, the next page asks you for the details about your redshift cluster ('Host', 'Port', 'Database', and 'Schema') and your credentials ('User' and 'Password').
In order to get details about your reshift cluster, log on to AWS and head over to the Clusters screen in your Amazon Redshift account. From the available list of clusters, select the one that you're trying to connect.
Firstly, it asks for 'Host'. The Host name is the 'Endpoint' listed within the 'General informtion' section. You will need to edit the given URL before adding it to your Tray.io authentication model.
For example, if your 'Endpoint' URL is: redshift-cluster-1.chjrudn4xw74.us-east-2.redshift.amazonaws.com:5427/dev, users will need to remove everything after :5427 in order to have valid information for the 'Host' field.
Once this is done, copy and paste the URL into said 'Host' field.



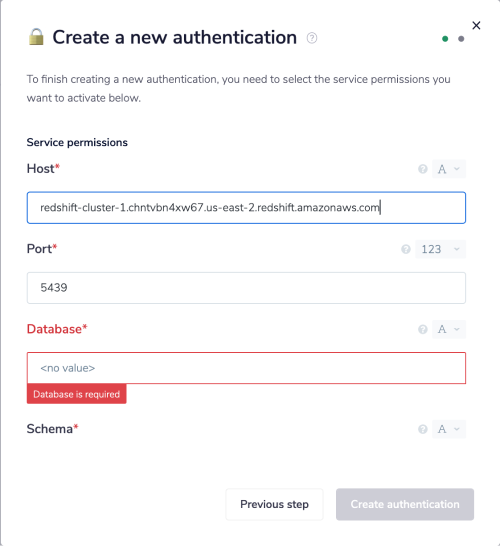
To get the 'Port' and 'Database' fields, head to your AWS account. On the same page from which you just copied your 'Host' URL, select the 'Properties' tab. This should be below the 'General information' section.
Scroll down to the 'Database configurations' area. Here, you will find your cluster's 'Database name' and 'Port'. Copy and paste this information into your Tray.io authentication popup model.


The 'Schema' field will depend on your individual use case, and the schemas you have available.
If you have created a variety of schemas (but are not sure which ones are available for your use), copy and paste the following query into Redshift's Query Editor: select * from pg_namespace;.
This query retrieves a full list of available schemas from the database, including the public schema.
You can then perform basic search queries in order to identify which tables are grouped under each schema. Users should enter the appropriate schema name in the 'Schema' field.

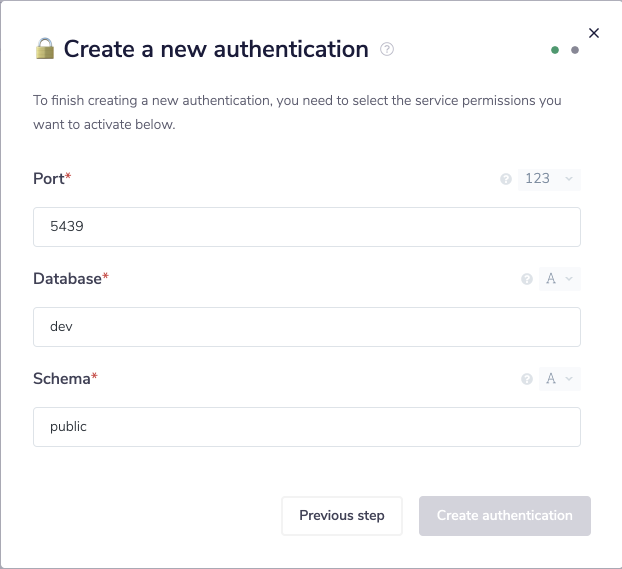
Finally, please provide your user credentials.
PLEASE NOTE: These user credentials are specific to the Redshift cluster and not AWS services.
In this example the primary user's credentials are displayed. Aka, the credentials that were created when first configuring the cluster.
If you want to use other individual's credentials for authentication, use the following query select * from pg_user; to retrieve their user details.
Remember that users will need certain access rights in order to query & manipulate the database.


Once you have added these fields to your Tray.io authentication popup window, click on the 'Create authentication' button. Go back to your settings authentication field (within the workflow builder properties panel), and select the recently added authentication from the dropdown options now available.
Your connector authentication setup should now be complete.
Notes on using RedshiftCopy
Run SQL queryCopy
The Run SQL query operation helps communicate with the Redshift database by executing raw specified SQL commands. The SQL commands can be used to perform actions like create and manipulate database objects, run queries, load tables, and modify the data in tables.
A sample query to create a table in the Redshift database would be something similar to this:
Create table purchase_details (order_id int, email varchar, total_price float, currency varchar)
The Amazon Redshift is based on PostgreSQL. Amazon Redshift and PostgreSQL have several very important differences that you must be aware of while working with the Redshift database. For information about how Amazon Redshift SQL differs from PostgreSQL, see the Amazon Redshift and PostgreSQL document.
For the ease of working with the Redshift PostgreSQL queries, refer to the Redshift's SQL commands document.
Available OperationsCopy
The examples below show one or two of the available connector operations in use.
Please see the Full Operations Reference at the end of this page for details on all available operations for this connector.
Example usageCopy
There are various ways in which you can upload (insert/update) data in to the Redshift tables based on your requirements and scenarios. Below are the few example work flows that will help you gain a better understanding of these ways:
Please note that the these demos which follow do not represent a 'fixed' way of working with Tray.io. They only show possible ways of working with Tray.io and the Redshift connector. Once you've finished working through this example please see our page Introduction to working with data and jsonpaths and Data Guide for more details.
In these examples, we have shown that you have received some customer data via the Webhook trigger, and now need to process it into Redshift. However users may have received this data in any number of other ways such as from the Salesforce or SurveyMonkey connector, through the CSV Editor, and so on.
Insert recordsCopy
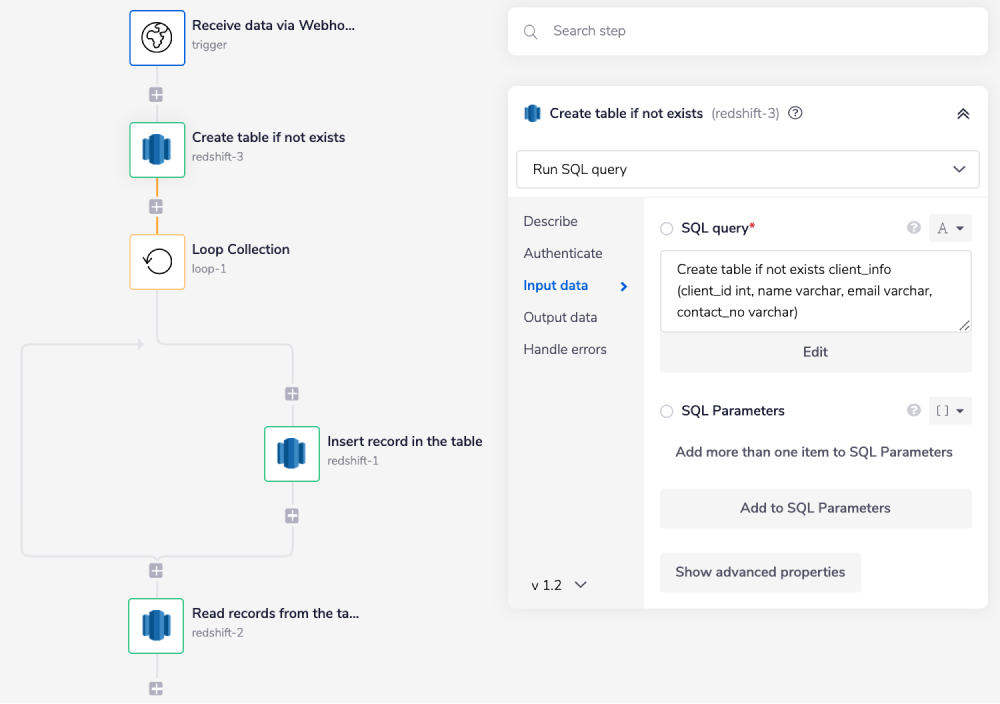
Below is an example of how you could potentially use the Redshift connector to insert new records into the Redshift database and read all the records from said database.
Upon receiving the records, the workflow checks whether the table we want to add these records to already exists in Redshift. If it does not, then the workflow creates a new table and then adds the received records to that table. Once the records are added, the workflow continues to read the records from the selected Redshift table.
This example demonstrates the following operations of the Redshift connector:
Run SQL query: Executes a raw specified SQL query on the chosen database.
Insert new rows: Inserts one or more rows into your chosen Redshift database.
Find rows: Finds and reads the rows from your chosen database based on the specified criteria.
The steps will be as follows:
Pull the client records from the source (a webhook trigger in this example) and create the table (if it doesn't exist) in the Redshift database.
Push the records one by one into the Redshift database using the Loop connector.
Read the records from the Redshift database.
The final outcome should look like this:


1 - Pull records & create tableCopy
When using a Webhook trigger 'When webhook is received, auto respond with HTTP 200' is the most common operation, unless you want to specify a custom response. Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
In this example, the records received by the Webhook are in JSON format:
1[{2"client_id": 82,3"name": "Renaldo Castaignet",4"email": "rcastaignet0@slashdot.org",5"contact_no": "578-493-4455"6},7{8"client_id": 79,9"name": "Arlen Grumbridge",10"email": "agrumbridge1@instagram.com",11"contact_no": "292-491-7708"12},13{14"client_id": 57,15"name": "Veronika Fitter",16"email": "vfitter2@google.com.au",17"contact_no": "457-411-5533"18},19{20"client_id": 68,21"name": "Tirrell Gladbach",22"email": "tgladbach3@discuz.net",23"contact_no": "714-514-0108"24},25{26"client_id": 90,27"name": "Emmalynne Gibbard",28"email": "egibbard4@accuweather.com",29"contact_no": "625-905-3040"30}31]
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Webform, etc., will have different results / views.
Next, add a Redshift connector and set the operation to 'Run SQL query'. Add the following query in the 'SQL query' field:
Create table if not exists client_info (client_id int, name varchar, email varchar, contact_no varchar)
The above query will verify if the specified table (in this case, client_info) exists in the Redshift database. If it exists, then the workflow proceeds. If it doesn't, then it creates the table based on the table information provided in the above SQL query.

2 - Add recordsCopy
Add a Loop connector with the 'List' field set to $.steps.trigger.body. You can use the connector-snake to generate this automatically.
JSONPATHS: For more information on what jsonpaths are and how to use jsonpaths with Tray.io, please see our pages on Basic data concepts and Mapping data between steps
CONNECTOR-SNAKE: The simplest and easiest way to generate your jsonpaths is to use our feature called the Connector-snake. Please see the main page for more details.

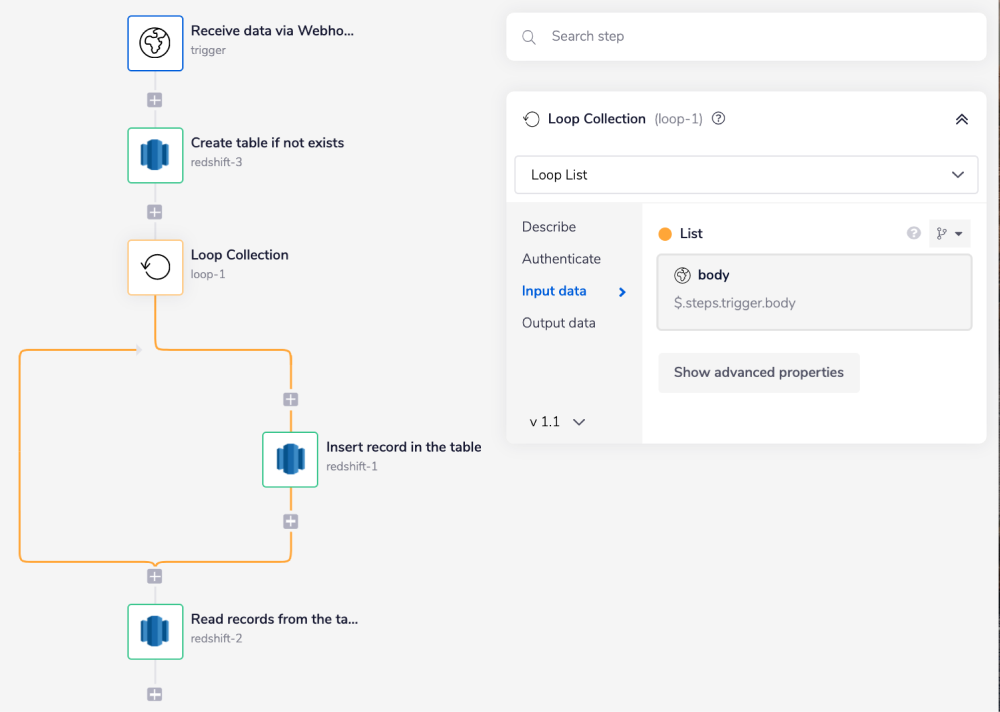
Next, add a Redshift connector inside the Loop connector and set the operation to 'Insert new rows'.
In the 'Rows to insert' field, add all the property names using the 'Add property to Row' button for the selected table.


Using the connector-snake once more, find the jsonpath for each field from the previous step.

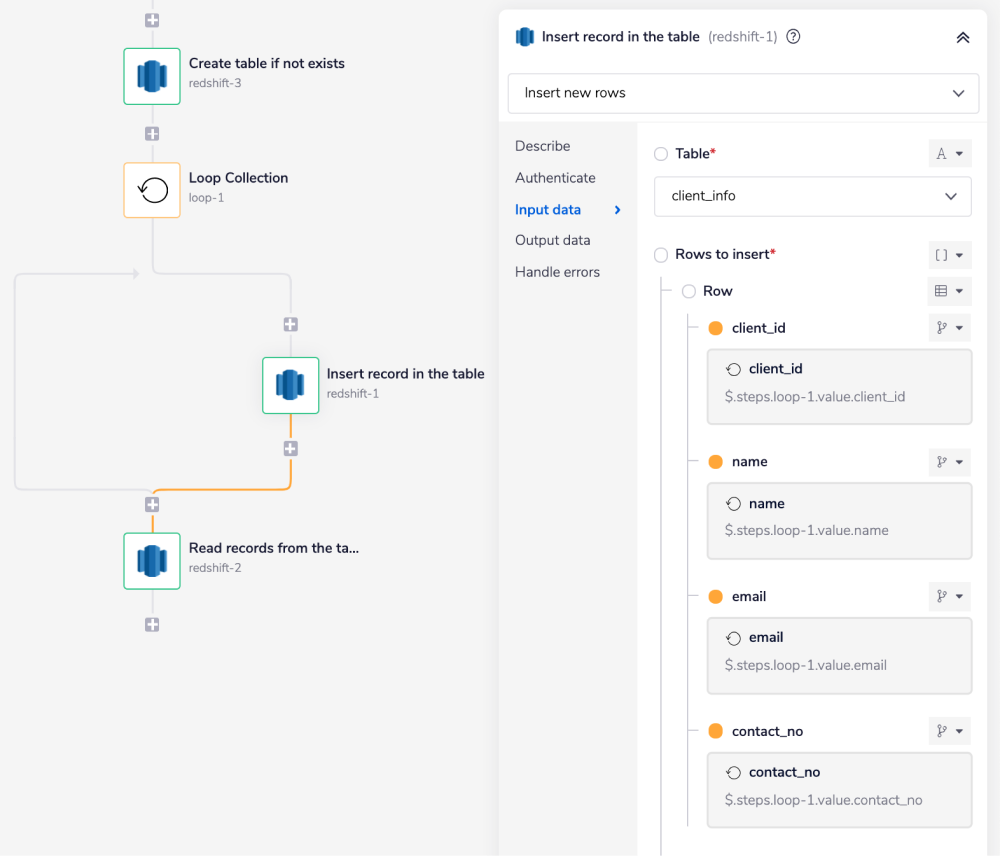
3 - Read recordsCopy
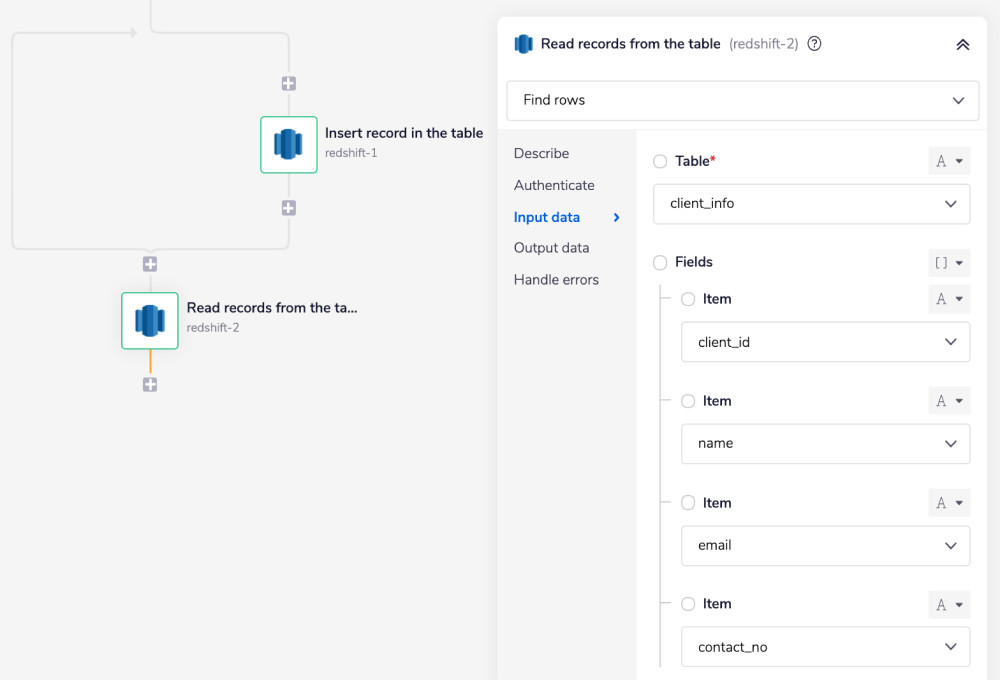
Add another Redshift connector and set the operation as 'Find rows'.
Under the 'Fields' section, select the field names (from the drop-down options) for the set table for which you would like to retrieve the information from.

Adding a record to a particular tableCopy
This workflow demonstrates how to insert records into multiple Redshift tables based on the received data.
The Redshift database considered in this example contains three tables, namely 'account', 'prospect', and 'sequenceState'. So depending on the tableName specified in the received data, the workflow will add the data to the specified table.
The steps will be as follows:
Pull the records from the source (a webhook trigger in this example) and extract the table name from the value of the tableName attribute.
Navigate the course of the workflow to the appropriate branch using the Branch connector based on the value (table name) received from the previous step.
Insert the new records into the appropriate Redshift table.
The final outcome should look like this:


1 - Pull records and extract the table nameCopy
When using a Webhook trigger 'When webhook is received, auto respond with HTTP 200' is the most common operation, unless you want to specify a custom response. Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
The records received by the Webhook are in JSON format:
{ "data": { "id": "20", "first_name": "Blake", "last_name": "Mosley", "phone": "+1 (956) 577-2515" }, "meta": { "tableName": "create.prospect" } }
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Outreach, etc., will have different results/views.
Next, add the Text Helper connector and set the operation to 'Get text after'.
The Text Helper connector using the 'Get text after' operation returns a substring based on the inputs provided.
As you can see in the image below, given a jsonpath to the 'String' field using the connector-snake ($.steps.trigger.body.meta.tableName) and a value to the 'Pattern' field as create.. It returns the substring between where the pattern was found depending on the 'Match number' 2 and the beginning of the string.

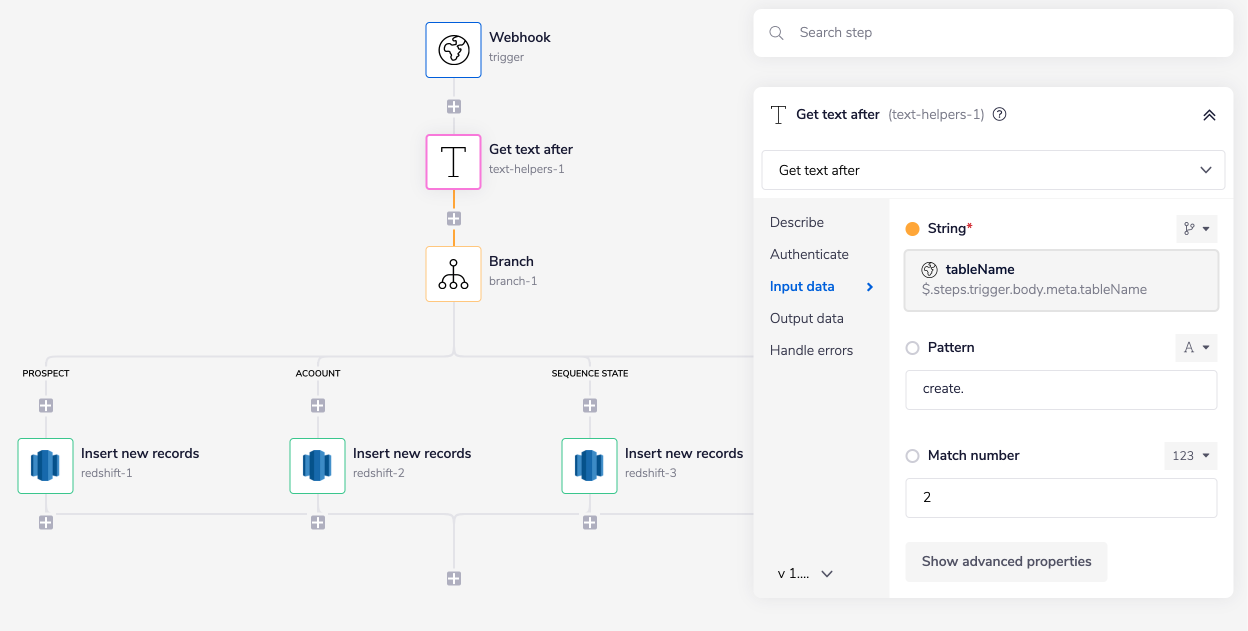
To understand this operation, consider the example JSON provided above. Based on the provided jsonpath and values for each field, the retrieved values are:
String:
create.prospectPattern:
create.Match number:
2
So when the values of the String and Pattern fields are compared, the match found is create.. So the operation provides the substring that comes after(second) the match. In this case, as you can see in the image below, the substring returned by the operation is prospect.

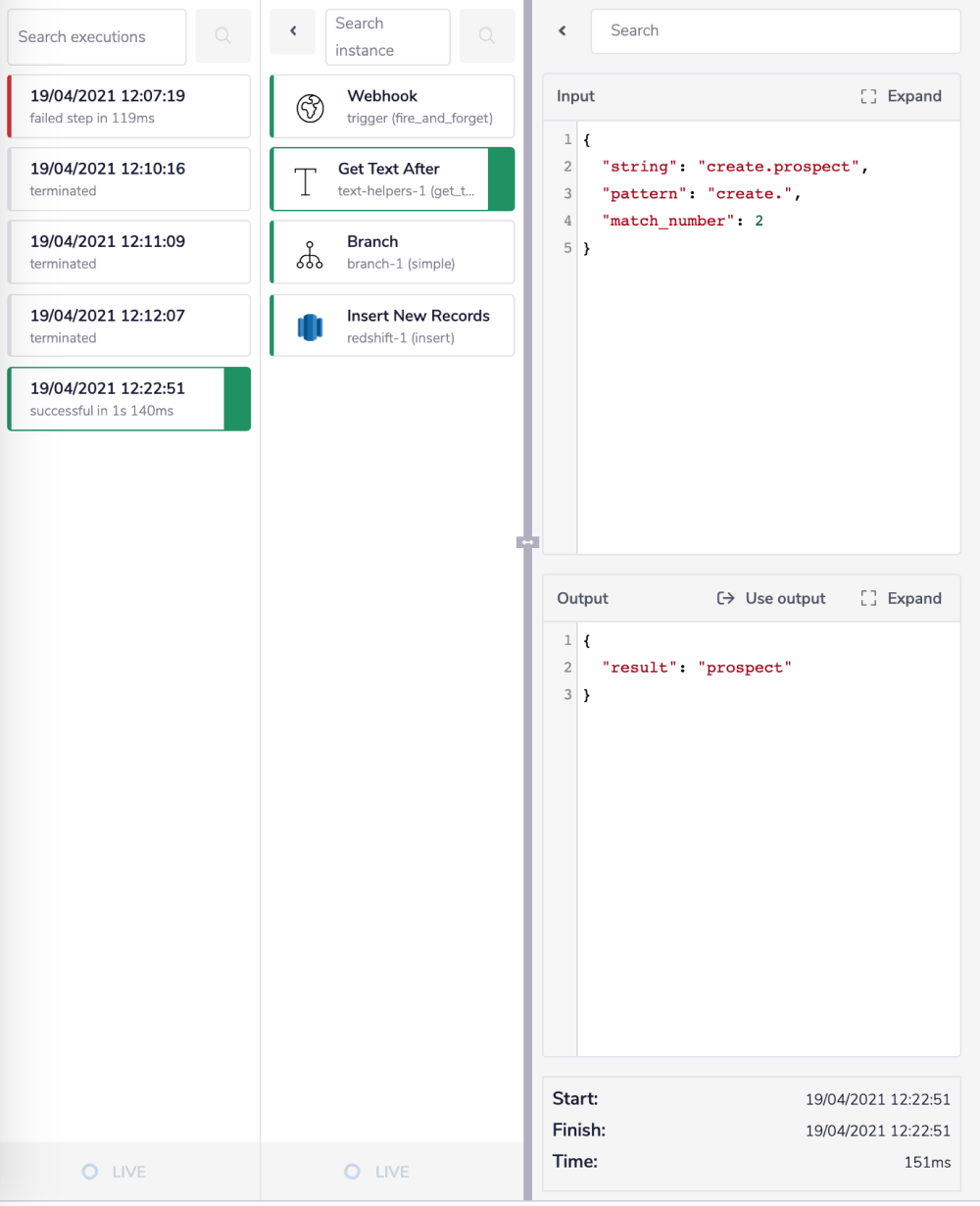
Based on this step's output, the workflow will navigate to the branch with the Label as 'Prospect'.
For more clarification on the pathways, you have available, open the Debug panel to view your step's Input and Output.
2 - Navigate and add recordsCopy
Add a Branch connector with the 'Value To Test' field set to $.steps.text-helpers-1.result. You can use the connector-snake to generate this automatically.
Set the 'Value' and 'Label' pair for each branch with the Redshift table names, as shown in the image below.

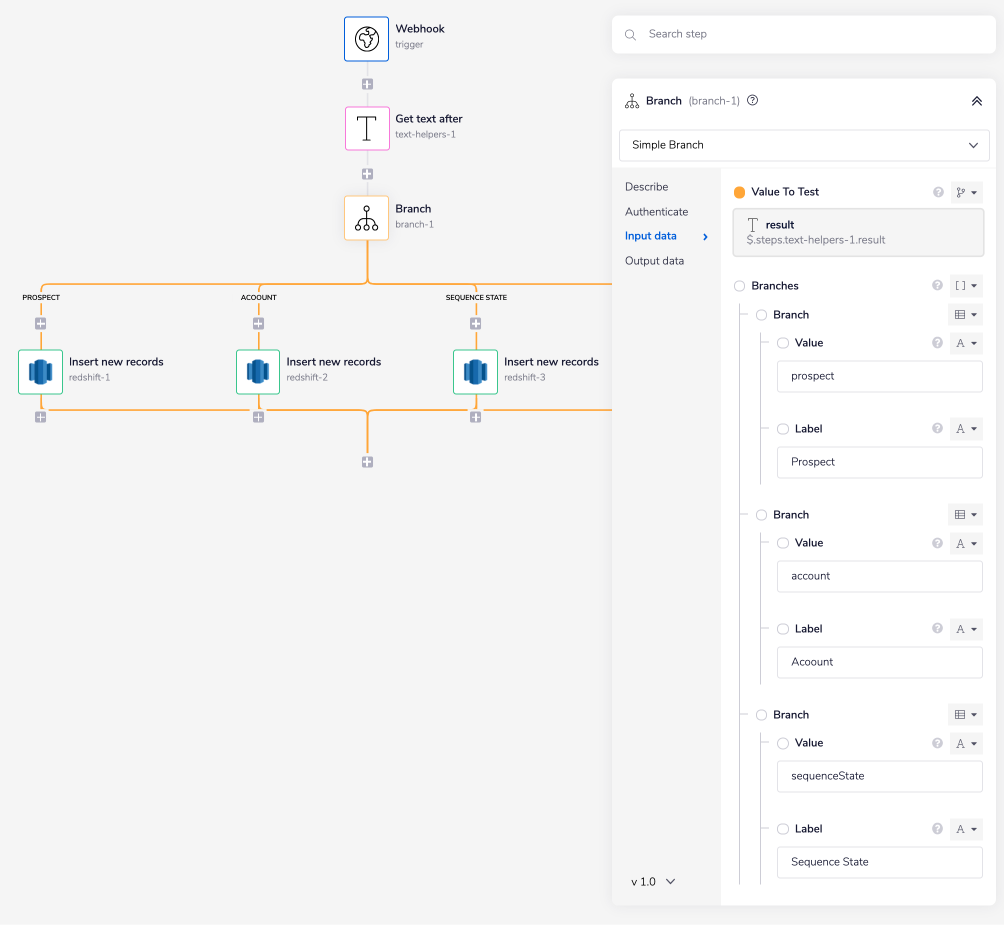
The Branch connector will navigate the workflow execution based on the input received from the previous step. The possible values you could receive from the previous step are 'prospect', 'account', and 'sequenceState', thus the three branches.
The third branch is an auto-generated 'Default' branch, which will terminate the workflow if the branch does not receive any of the three values mentioned above as an input.
For the workflow to terminate, add the Terminate connector under this fourth branch, i.e., the 'DEFAULT' branch.
Next, add the Redshift connector under each branch except the 'DEFAULT' branch, and set the operation to 'Insert new rows'.
As you can see, the 'Table' and the 'Rows to insert' fields are mandatory.
Select the appropriate table name from the drop-down options based on the branch your Redshift connector is on. As you can see we have selected the table name for the first branch as prospect.
Using a connector-snake find the jsonpath for the 'Row' field from the Trigger step. It should appear similar to this: $.steps.trigger.body.data.

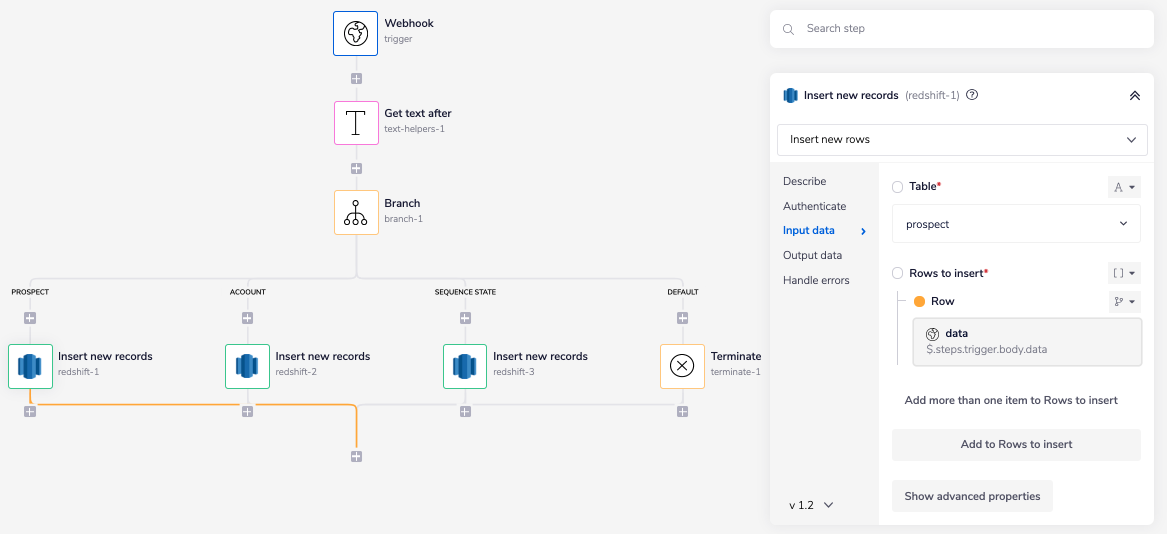
Similarly, add values for the 'Table' and the 'Rows to insert' fields for the Redshift connectors under the 'ACCOUNT' and 'SEQUENCE STATE' branches.
The Insert new rows operation will insert the records received through the Webhook trigger in the selected Redshift table.
Add or update recordCopy
The below example demonstrates how you could potentially use the Redshift connector to insert and update the records into the Redshift database.
In this workflow, the record to be uploaded to the Redshift database is received through the Webhook trigger. The received record includes the event attribute which specifies if the record is to be created or updated.
The steps will be as follows:
Pull the records from the source (a webhook trigger in this example) and navigate the course of the workflow to the appropriate branch using the Branch connector based on the value (event) received from the previous step.
Insert or update the record to the Redshift database.
The final outcome should look like this:

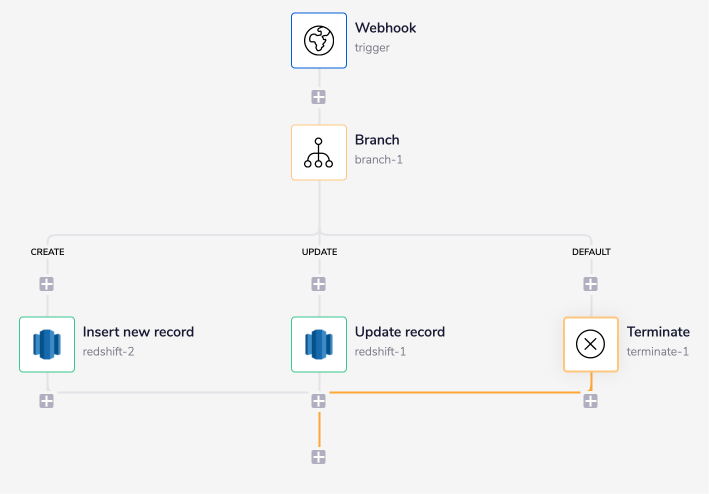
1 - Pull records and navigateCopy
When using a Webhook trigger 'When webhook is received, auto respond with HTTP 200' is the most common operation, unless you want to specify a custom response. Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
The records received by the Webhook are in JSON format:
1{2"data": {3"id": "20",4"first_name": "Blake",5"last_name": "Mosley",6"phone": "+1 (956) 577-2515"7},8"meta": {9"event": "create"10}11}
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Outreach, etc., will have different results/views.
Next, add the Branch connector with the 'Value To Test' field set to $.steps.trigger.body.meta.event. You can use the connector-snake to generate this automatically.
Set the 'Value' and 'Label' pair for the first two branches as 'create' and 'update' as shown in the image below.

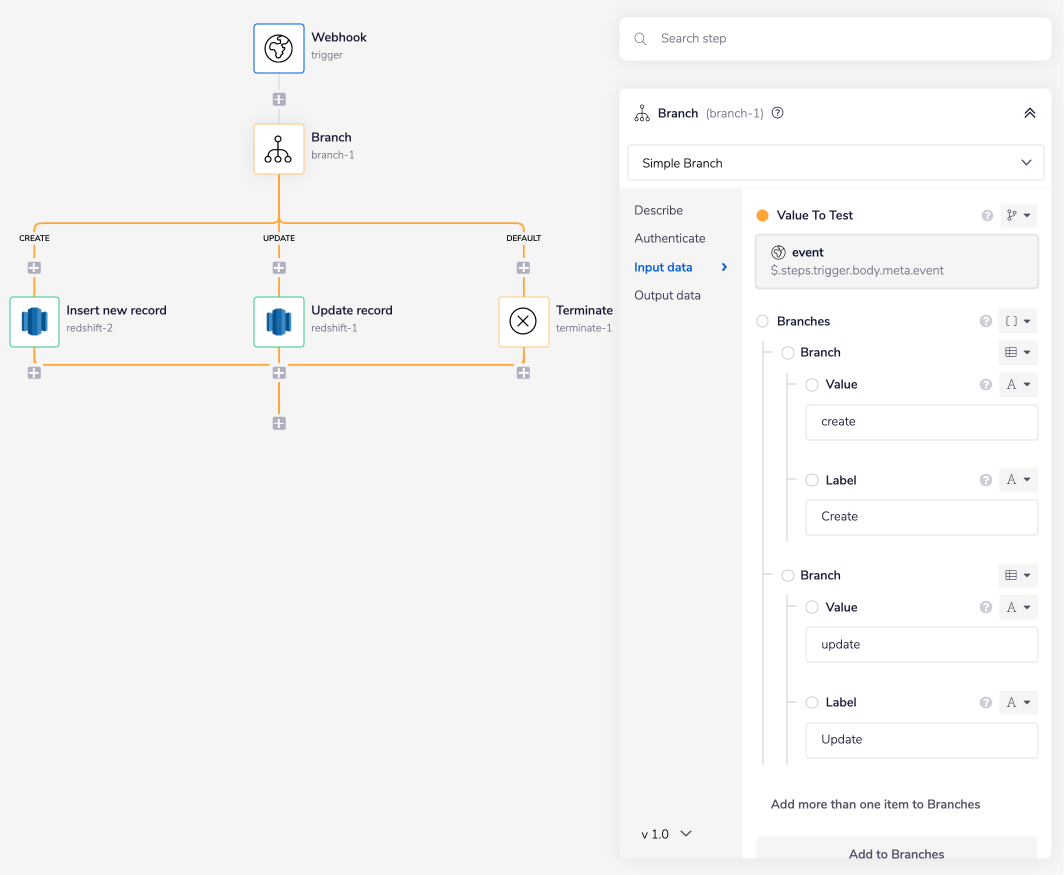
The Branch connector will navigate the workflow execution based on the value of the event attribute received in the JSON data from the trigger. The possible values you could receive are 'create' and 'update', thus the first two branches.
The third branch is an auto-generated 'Default' branch, which will terminate the workflow if the branch does not receive any of the two values mentioned above as an input.
For the workflow to terminate, add the Terminate connector under this fourth branch, i.e., the 'DEFAULT' branch.
2 - Insert or update the recordCopy
Now, add the Redshift connector under each branch except the 'DEFAULT' branch.
As you can see in the image below, the first Redshift connector under the 'CREATE' branch will insert a new record into the Redshift database. The second Redshift connector under the 'UPDATE' branch will update the received record into the Redshift database.

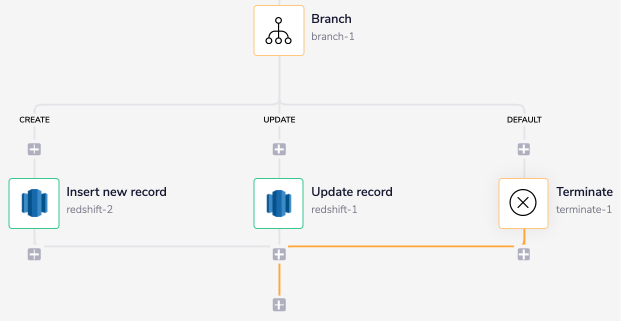
The two Redshift connectors for insert and update operation can be configured as follows:
Redshift connector to insert a record:
To insert the record, set the operation to 'Insert new rows'.
As you can see, the 'Table' and the 'Rows to insert' fields are mandatory.
Select the table name of your choice from the available drop-down options. As you can see, in this example, we have selected the table name as customer_details.
Using a connector-snake find the jsonpath for the 'Row' field from the Trigger step. It should appear similar to this: $.steps.trigger.body.data.


Now, based on the selected table and the jsonpath for the received data, the workflow will insert the received record into the selected Redshift table.
Redshift connector to update a record:
To update the record, set the operation to 'Update rows'.
Set the values for the 'Table' and the 'Rows to insert' fields similarly as we did above.
Before updating the record, the Update rows operation matches the existing 'id' from the selected Redshift table with the ID of the data received from the trigger: $.steps.trigger.body.data.id.
Thus, as you can see in the image below, the condition is set to specify the id of the existing record that needs to be updated.


Now, based on the specified table, jsonpath, and the condition, the workflow will locate and update the record if it already exists.
Managing DataCopy
Batch insertion of dataCopy
For efficiency purposes, and to reduce the amount of calls you make to Redshift, you want to avoid a situation where you are looping through data and inserting it row by row, such as the following:

The following workflow shows a simple example of how you can loop through batches of e.g. 200 records so that you can make e.g. 10 calls of 200 instead of 2000 individual calls.
Exactly how you will do this will depend on the service you are pulling records from

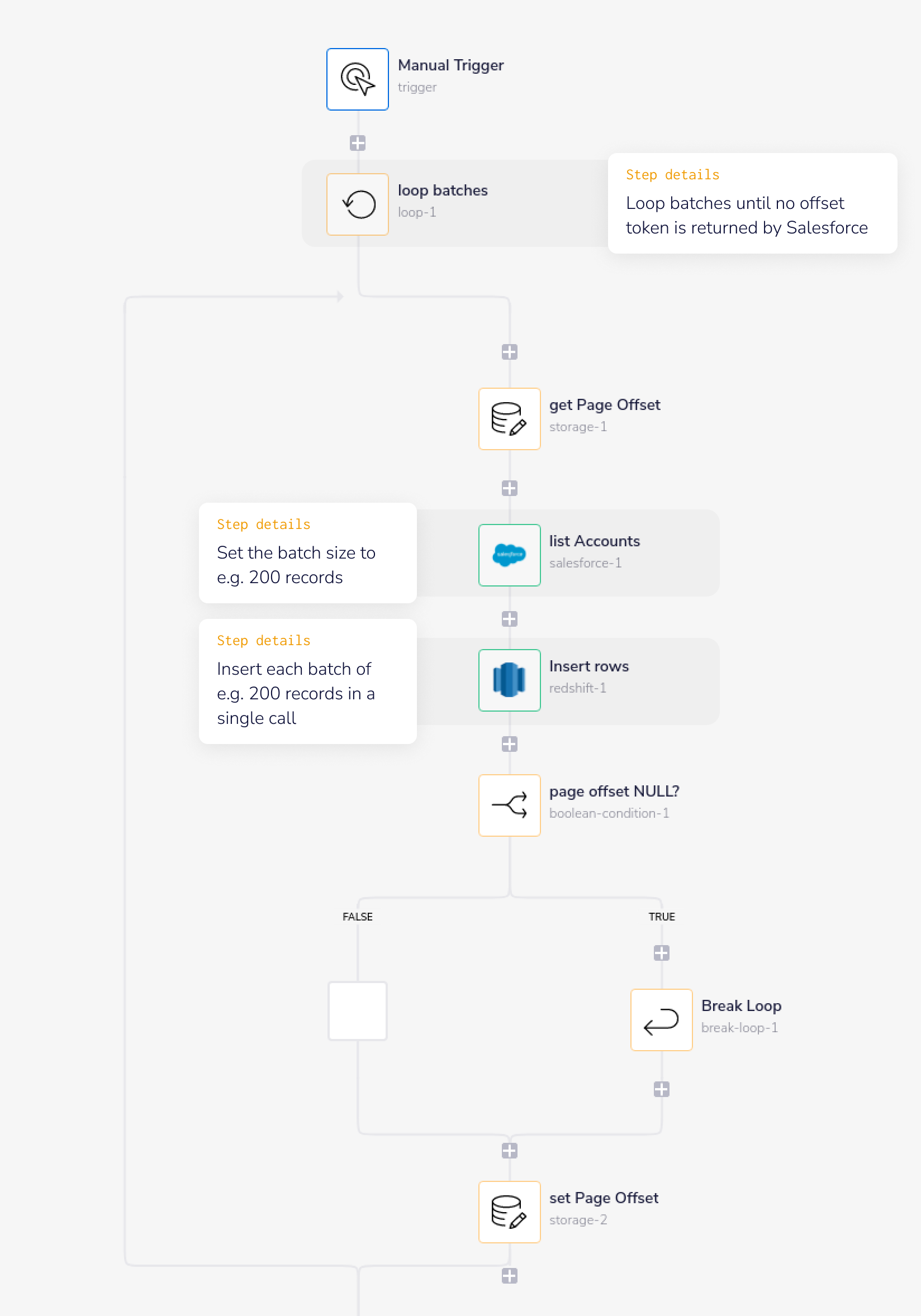
Loop batches is the main loop which is set to 'loop forever' and keeps running until Salesforce doesn't return an offset token - indicating there are no more batches to loop through.

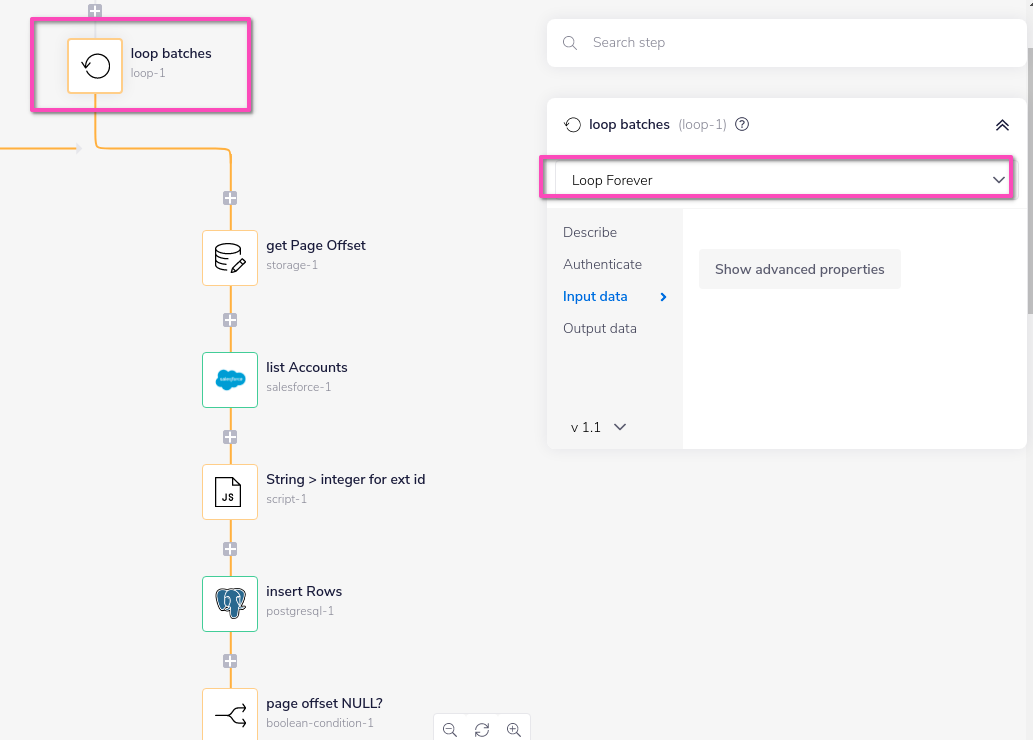
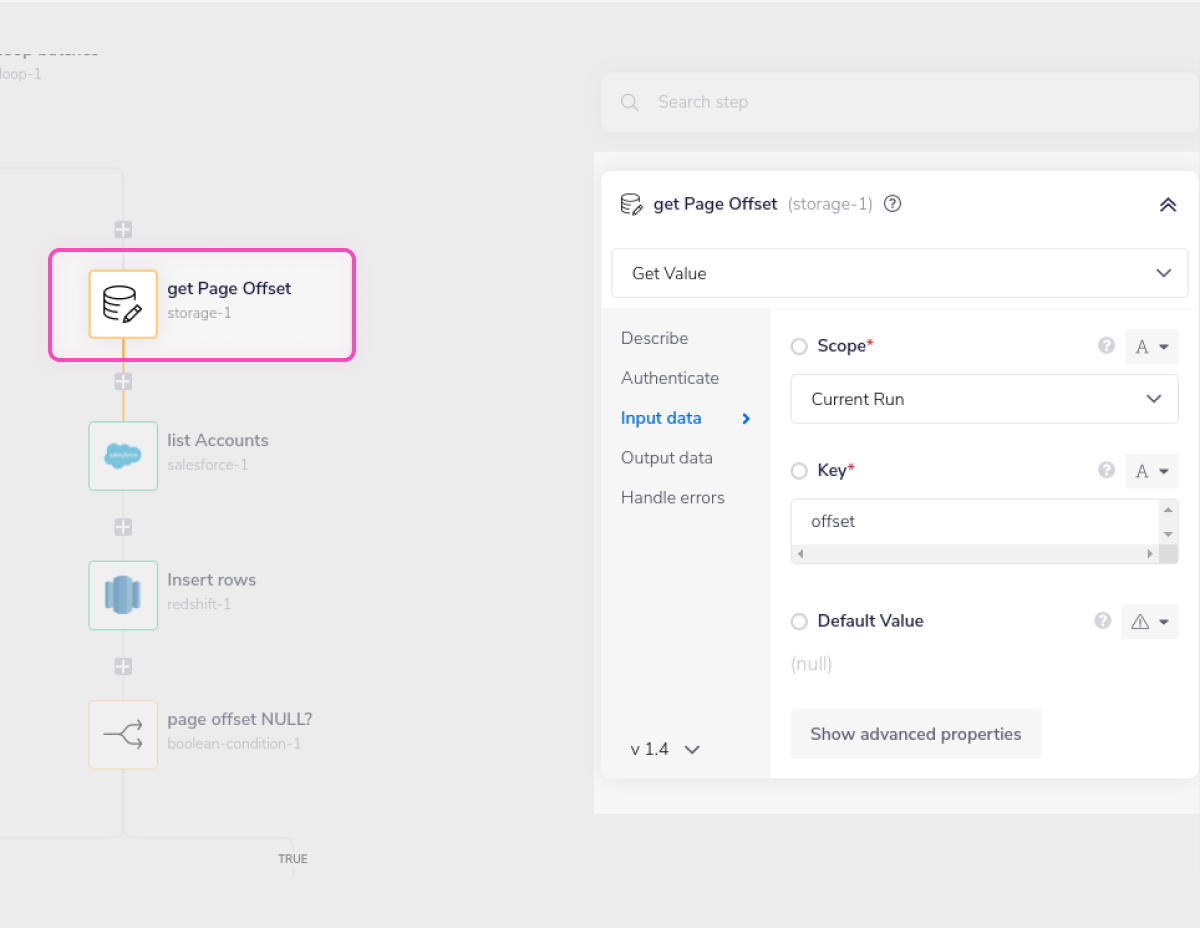
get page offset gets the offset token returned by Salesforce in the previous loop, so that Salesforce knows where to start retrieving this batch of records.

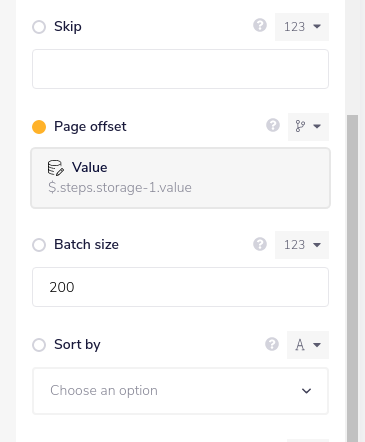
list accounts specifies what record type and fields to retrieve from Salesforce.

It also passes the page offset token, and sets the batch size.

USER TIP: If necessary you can always transform the extracted data before you load it into your database. Transformation could be anything such as formatting the data or changing the data type to match the accepted database format. To learn more, please see our ETL documentation
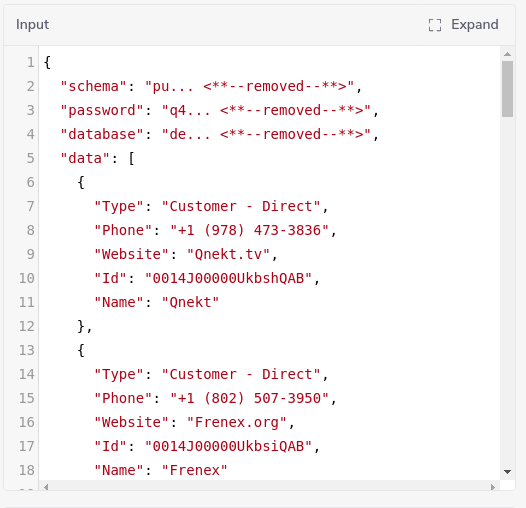
Insert rows then inserts the data from the current list into the selected Redshift table in a single call.

The payload sent to Redshift is in the form of an array which matches the format accepted by Redshift.

page offset NULL? uses
$.steps.salesforce-1.next_page_offsetto check if Salesforce has returned an offset token to indicate more batches are to be processed. If not, then the main loopbatches loop is broken.set page offset then stores the offset token to be retrieved at the start of the next batch.

Processing dynamic dataCopy
Sometimes, depending on the data source, your workflow may receive dynamic data payloads - i.e., the attributes within may vary for each execution of your workflow.
Let's assume an example where you wish to insert some data into a Redshift database.
The data that you have received for the first execution of your workflow is in this format:
1{2"data": {3"id": "129273",4"attributes": {5"department": "IT",6"branch": "London"7}8},9"meta": {10"deliveredAt": "2021-01-29T07:52:28.094+00:00"11}12}
For the second execution, your workflow may receive the data with more attributes like this:
1{2"data": {3"id": "129273",4"attributes": {5"department": "IT",6"branch": "London",7"country": "uk",8"zip": "JU59KL"9}10},11"meta": {12"deliveredAt": "2021-01-29T07:52:28.094+00:00"13}14}
PLEASE NOTE: It is essential that the attributes received in the JSON data correspond to the column names in your Redshift database table.
So in such a situation, where it is difficult to gauge the attributes you may receive in your data for each execution. We cannot map each attribute with their respective column names in order to upload the data in the Redshift table, i.e., something like this, as shown in the image below, is not possible:
To understand the mapping of each attribute with the column name, please refer to the Insert records workflow explained above.
So as a solution, you have to upload the data in bulk, i.e., in one go. This is possible only if the received JSON data has a flat structure.
The best way to transform a nested JSON structure into a flat structure is by using a Data Mapper connector.
So the following workflow demonstrates how you could deal with dynamic data using a Data Mapper connector that flattens the nested JSON and uploads this data into your Redshift database table.
PLEASE NOTE: The Data Mapper connector, as explained in this workflow, can be used only with the dynamic data for which you know the possible list of attributes.
In this example, we show data being received via the Webhook trigger - i.e., a scenario whereby you have configured an external service to automatically send new record data to your Tray.io workflow.
In practice, you can receive data in any structure, and in other ways, such as from any pre-built Tray.io service trigger or from a previous workflow step which has pulled data from another source (e.g., Salesforce 'Find Records', CSV Reader, etc.)

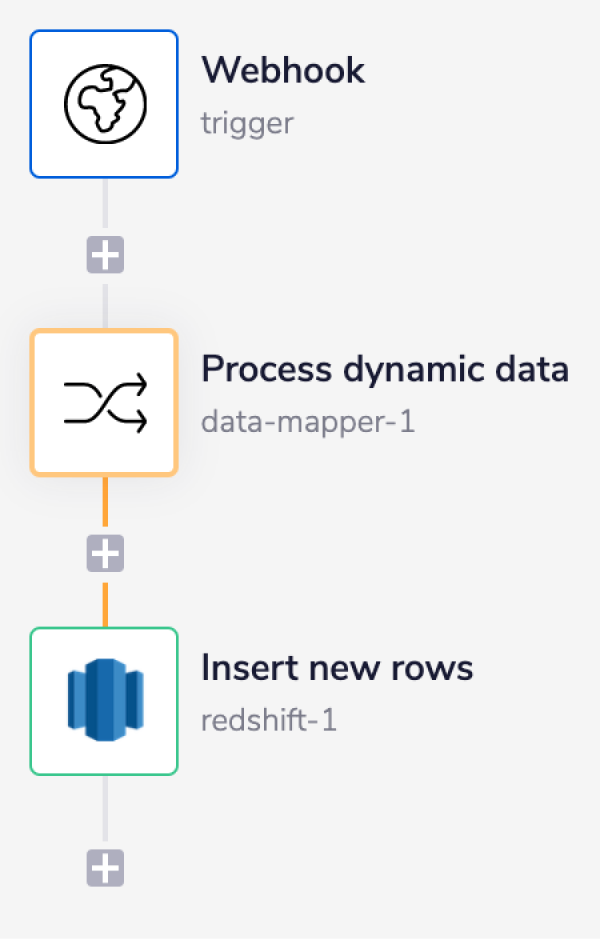
The Webhook trigger with operation as 'Auto respond with HTTP 200' listens for the incoming data.
The Process dynamic data step is a Data Mapper connector step which flattens the received JSON data in order to handle the incoming dynamic data.
The 'Mapping' field transforms the nested structure i.e attributes.[column_name] to a flat structure, i.e. just the [column_name]. The 'Mapping' field contains a list of all the possible attributes that you wish to get a flat structure for.

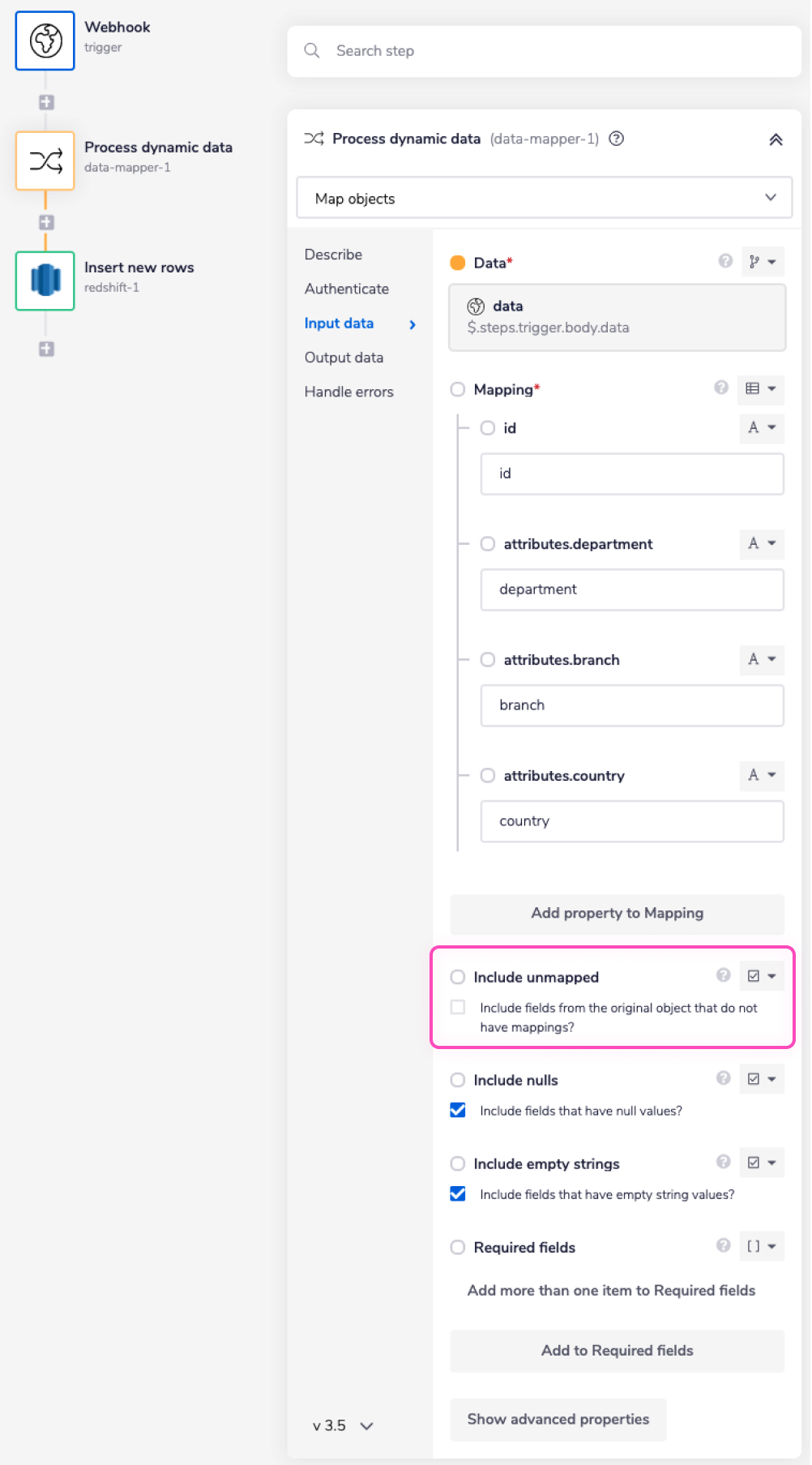
Make sure to uncheck the 'Included unmapped' field. If you do not uncheck this field, it will include the fileds from the received JSON data that you haven't listed in the Mappings field, i.e., something like this:


If the 'Included unmapped' field is unchecked the expected flat JSON output should look like this:


The Insert new rows step inserts new rows based on the flatten JSON data received from the previous step
$.steps.data-mapper-1in the selected Redshift table (explained in detail below).


Advanced topicsCopy
Redshift bulk insertCopy
The below example demonstrates how you could potentially insert a huge amount of records in one go into a Redshift table.
We are using AWS S3 as an intermediate data storage solution before we insert the received records into Redshift.
We are using S3 as intermediate storage because S3 has a large storage capacity, which helps when dealing with huge amounts of data. It is easy to transfer all the records from S3 to Redshift in one go - minimizing the number of calls made to Redshift.
We can also use the Redshift COPY command, which has significant speed advantages when dealing with large amounts of data.
In this example the idea is that the workflow is triggered every day at a scheduled time. Once triggered, it lists the records from the service in use.
For simplicity and better understanding, we have used an Object Helpers connector that is parsing a JSON that contains a set of records. In reality this could be any service, such as Gong.io, with an operation set to 'List users' or Salesforce with the 'Find records' operation.
The JSON is as follows:
1[2{3"data": {4"id": "6012fe453f38ecab86530e97",5"first_name": "Brooks",6"last_name": "Hendrix",7"phone": "+1 (990) 546-2598"8},9"meta": {10"event": "create",11"type": "prospect"12}13},14{15"data": {16"id": "6012fe454256655c4da94179",17"first_name": "Crane",18"last_name": "Lindsey",19"phone": "+1 (932) 505-2355"20},21"meta": {22"event": "create",23"type": "account"24}25},26{27"data": {28"id": "6012fe45c0d81c6f14a78c4d",29"first_name": "Blake",30"last_name": "Mosley",31"phone": "+1 (956) 577-2515"32},33"meta": {34"event": "update",35"type": "prospect"36}37},38{39"data": {40"id": "6012fe45fd903b3e38f8f5ef",41"first_name": "Francis",42"last_name": "Mcdowell",43"phone": "+1 (940) 447-2645"44},45"meta": {46"event": "update",47"type": "account"48}49},50{51"data": {52"id": "6012fe4509b4461450de082c",53"first_name": "Sue",54"last_name": "Wilkerson",55"phone": "+1 (905) 508-3504"56},57"meta": {58"event": "update",59"type": "prospect"60}61},62{63"data": {64"id": "6012fe45150b03d02a887d2b",65"first_name": "Berry",66"last_name": "Riggs",67"phone": "+1 (872) 460-3574"68},69"meta": {70"event": "update",71"type": "prospect"72}73},74{75"data": {76"id": "6012fe45c86ec53152c0adcd",77"first_name": "Ray",78"last_name": "Nichols",79"phone": "+1 (859) 492-3067"80},81"meta": {82"event": "update",83"type": "prospect"84}85},86{87"data": {88"id": "6012fe45dbfaabd167439bde",89"first_name": "Reeves",90"last_name": "Carrillo",91"phone": "+1 (834) 541-2561"92},93"meta": {94"event": "update",95"type": "account"96}97}98]

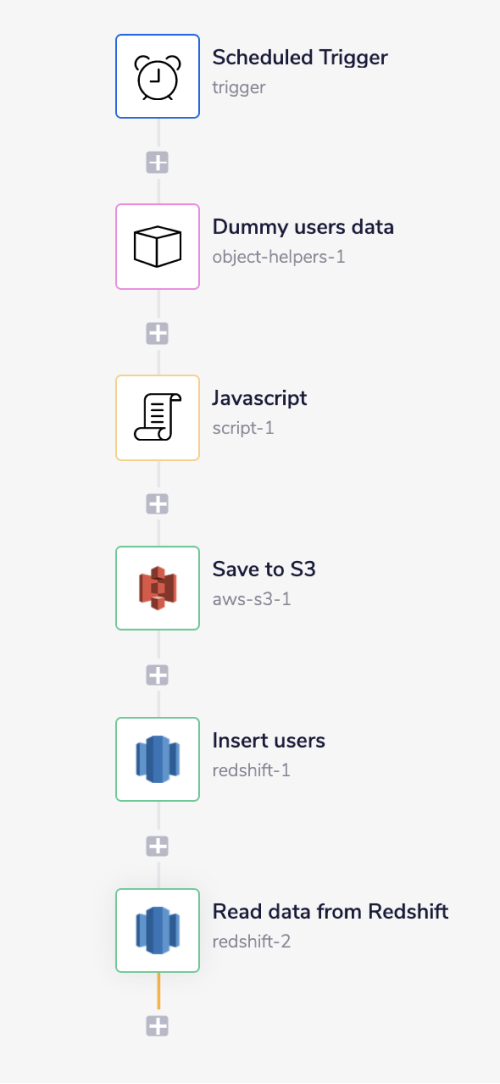
Setup a Scheduled Trigger with custom configurations tailored as per your requirement. For example, we have configured the trigger to be fired at noon 'Every Day'.
The Dummy users data step is an Object Helpers step with operation as 'JSON parse'. This step will parse the JSON data mentioned above.
The Script step converts the object received from the previous step into a JSON string (explained in detail below).
The Save to S3 step is an AWS S3 connector step that saves the JSON string received from the previous step into a specified bucket_name/file_name (explained in detail below).
The Insert users step saves the records received from the Save to S3 step into the Redshift table.
The Read data from Redshift step uses the 'Run SQL query' operation with
Select * from prospectquery. This query will return all the records from the specified table, i.e., prospect.
This step will verify if all the received records are added to the specified Redshift table or not. It is required as the 'copy' command used in the previous step does not return the success information or total count of rows added to the Redshift table.
Script step: explanationCopy
The Script connector using the 'Execute Script' operation converts the received object from the previous step into a JSON string.
It is necessary to stringify the JSON to store it in a file within an S3 bucket.
As you can see in the image below, the operation accepts the jsonpath for the data from the Object Helpers, i.e., the Dummy users data step as an input value: $.steps.object-helpers-1.result.


The Script connector using the following script converts the received JSON data into a JSON string:
1// You can reference the input variables using input.NAME2exports.step = function(input) {3return input.data.map(d => JSON.stringify(d)).join("");4};
Save to S3: explanationCopy
In this step, we are storing the JSON string received from the Script step into a specified file within an S3 bucket.
To do so, we are using the S3 connector's 'Put Object (Text)' operation.
The 'Bucket name' field accepts the name of the S3 bucket which you wish to use for this operation.
The 'Object Key' is a complete path of the file you wish to store the received JSON string into. In this case it is: tray-prospects/prospects. tray-prospects/ is a bucket name and prospects is a file name.
'Content' is nothing but the JSON string that you wish to store in the S3 bucket. In this case it is a jsonpath of the result from the Script step: $.steps.script-1.result.

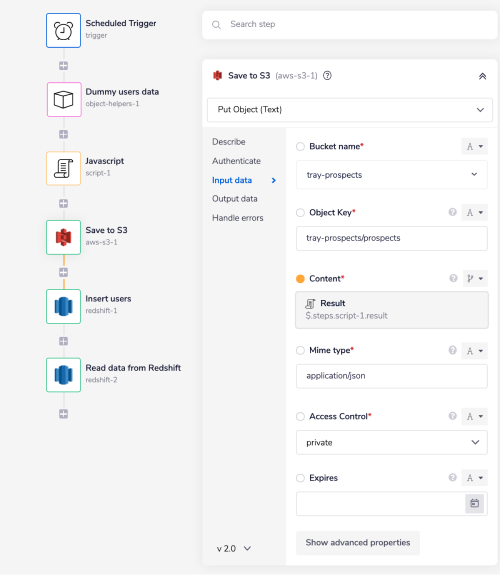
As a result this step will store the JSON string received from the previous step into S3 at this location: tray-prospects/prospects.
Insert users: explanationCopy
The Redshift connector using the 'Run SQL query' operation will store the data received from the S3 connector into the specified redshift table. The query used to do so is as follows:
begin;
copy prospect
from 's3://tray-prospects/prospects'
format as json 's3://tray-prospects/prospectJsonPath.json'
iam_role 'arn:aws:iam::312938373754:role/s3-redshift-readonly';
end;
The SQL query uses the 'copy' command to copy the entire data from the within the S3 bucket to the Redshift table. To understand the copy command in detail, refer to the Using the COPY command to load from Amazon S3 document.


There are several parts to the above query, let's understand them line by line:
copy prospect: The first line within the query mentioned above specifies the destination you wish to copy the records to, i.e., the Redshift table name.
It involves the copy operation and the valid [Redshift table name], i.e., prospect in this case.
from '
s3://tray-prospects/prospects': The second line specifies the data source, i.e., the complete path of the file within the S3 bucket.
It involves the from operation and the the complete path of the file within the S3 bucket: s3://[S3_bucket_name]/[file_name].
format as json '
s3://tray-prospects/prospectJsonPath.json': Here, you need to provide the structure of the JSON object in use. The 'format as json' operation helps you specify the file name containing the JSON structure.
In this case, we have created a file in the 'tray-prospects' S3 bucket with the name 'prospectJsonPath.json'. This file contains the below-mentioned JSON structure. This structure is based on the sample JSON mentioned above.
12{3"jsonpaths": [4"$.data.id",5"$.data.first_name",6"$.data.last_name",7"$.data.phone"8]9}
To know more about JSON format refer to the COPY from JSON format document.
iam_role '
arn:aws:iam::312938373754:role/s3-redshift-readonly': In this copy operation the AWS S3 service is accessing Amazon Redshift features on your behalf. For this, you need to create an IAM role with special permissions to allow the S3 to access Redshift.
Follow the instructions mentioned in the Authorizing Amazon Redshift to access other AWS services on your behalf document to create the IAM role.
Once done, you can mention the newly created IAM role beside the iam_role operation as done in the query above.