
Microsoft SQL Database 4.3
Interact with Microsoft's SQL database service.
OverviewCopy
The tray.io Microsoft SQL database connector gives you the ability to interact with Azure's SQL database service.
Connecting to your databaseCopy
You can authenticate with Azure using the login credentials for the database you wish to access.
The username and password related to the server admin or Azure AD user authorized to access the database. The Server field relates to the server name property in the overview panel of your database in the Azure portal.
IMPORTANT!:Be sure to whitelist the following IP addresses to allow Tray to connect with your database, by editing the firewall rules in the overview panel of your account
52.40.200.248
52.39.10.61
52.26.59.155It is extremely important that your Microsoft SQL database is only accessible with a strong username and password combination when whitelisting these IP addresses, as they will be used by anyone using the connector in a Tray workflow.
AuthenticationCopy
Within the workflow builder, highlight the Microsoft SQL database connector.
In the Microsoft SQL database connector properties panel to the right of the builder, click on the Authenticate tab and the 'New authentication' button.


This will result in a Tray.io authentication pop-up modal. The first page will ask you to name your authentication and select the type of authentication you wish to create ('Personal' or 'Organisational').
The next page asks you for your 'User name', 'Password', 'Server' and the 'Database'. There are also 'Encrypt' and 'Port' options depending on your use case.

The 'User name' and 'Password' are the same as the authentication credentials you used to login into the Microsoft SQL database.
The 'Server' property refers to the server name. By default, the server name is: MSSQLSERVER. As a user, you may have several to choose from. Open up SQL Server Configuration Manager and navigate to the SQL Server Services panel to view your options.
Once you are there, a new panel should open up to the right-hand side, displaying all the available servers (listed by name).
Only the server instances which begin with SQL Server and have their SQL ID's following in parenthesis are applicable.
Take for instance, a server listed in the below image: SQL Server (SQL2008). This is an ideal candidate because it meets the parameters mentioned above. The only aspect of this name that is needed for the authentication process is the SQL ID, aka: SQL2008.
Copy the ID and paste it into your Tray.io authentication modal.

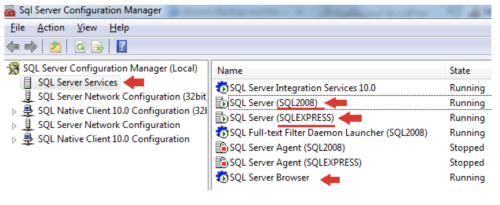
IMPORTANT!: Please make sure that your 'SQL Server' and 'SQL Server Browser' services are up and running, as displayed in the image above, before continuing. Otherwise, you won't be able to connect to the servers and complete the authentication process with Tray.io.
The 'Database' property refers to the database name. You will need to run a Microsoft SQL database query in order to obtain this.
Please refer to the following Microsoft documentation page for variants of this.
The 'Encrypt' field is automatically checked for you in the authentication modal. Feel free to uncheck this if it does not suit your use case.
Regarding the 'Port' property, by default the SQL database uses port number TCP: 1433.
This can be changed to suit your preferences, which is why your current database may not be set to the default port number. It may have already been changed for security reasons.
For more information on how to discover your actual port number, please see this article on Different ways to find your SQL Server Port Number for more details.
Once you have added these fields to your Tray.io authentication pop-up window, your modal should look similar to this:

Click on the 'Create authentication' button to continue.
Go back to your settings authentication field (within the workflow builder properties panel), and select the recently added authentication from the dropdown options now available.
Your connector authentication setup should now be complete.
Notes on using Microsoft SQL databaseCopy
Run SQL queryCopy
The Run SQL query operation helps communicate with the Microsoft SQL database by executing raw specified SQL commands. The SQL commands can be used to perform actions like create and manipulate database objects, run queries, load tables, and modify the data in tables.
A sample query to create a table in the Microsoft SQL database would be something similar to this:
Create table purchase_details (order_id int, email varchar(20), total_price float, currency varchar(20));
For the ease of working with the Microsoft SQL database queries, refer to the Microsoft SQL database document.
Insert rowsCopy
Microsoft SQL database connector's 'Insert rows' operation helps insert one or more rows into the Microsoft SQL database.
There are two ways to insert rows into the Microsoft SQL database.
Refer to the Example usage section below for detailed examples on both ways.
Inserting data row by rowCopy
When inserting data row by row, the 'Insert rows' operation accepts a jsonpath for each column separately.


In this case, the expected JSON data is mainly in the following format:
1{2"data": {3"id": "20",4"first_name": "Blake",5"last_name": "Mosley",6"phone": "+1 (956) 577-2515"7}8}
To learn more refer to the Add or update record example.
Inserting multiple rows in a single callCopy
When inserting data in a single call, the 'Insert rows' operation accepts a jsonpath for the entire data from the source.

In this case, the expected JSON data should be an array of key-value objects:
1{2"data": [3[{4"key": "id",5"value": "20"6},7{8"key": "first_name",9"value": "Blake"10},11{12"key": "last_name",13"value": "Mosley"14},15{16"key": "phone",17"value": "+1 (956) 577-2515"18}19]20]21}
You may need to format the incoming data into the format accepted by Microsoft SQL database connector. To learn more refer to the Batch insertion of data example.
Available OperationsCopy
The examples below show one or two of the available connector operations in use.
Please see the Full Operations Reference at the end of this page for details on all available operations for this connector.
Example usageCopy
There are various ways to upload (insert/update) data into the Microsoft SQL database tables based on your requirements and scenarios. Below are the few example workflows that will help you gain a better understanding of these ways:
Please note that the these demos which follow do not represent a 'fixed' way of working with Tray.io. They only show possible ways of working with Tray.io and the Microsoft SQL database connector. Once you've finished working through this example please see our page Introduction to working with data and jsonpaths and Data Guide for more details.
In these examples, we have shown that you have received some customer data via the Webhook trigger, and now need to process it into Microsoft SQL database. However users may have received this data in any number of other ways such as from the Salesforce or SurveyMonkey connector, through the CSV Editor, and so on.
Insert recordsCopy
Below is an example of how you could potentially use the Microsoft SQL database connector to insert new records into the Microsoft SQL database and read all the records from said database.
This example demonstrates the following operations of the Microsoft SQL database connector:
Run SQL query: Executes a raw specified SQL query on the chosen database.
Insert rows: Inserts one or more rows into your chosen Microsoft SQL database.
The steps will be as follows:
Pull the client records from the source (a webhook trigger in this example).
Push the records one by one into the Microsoft SQL database using the Loop connector.
Read the records from the Microsoft SQL database.
The final outcome should look like this:

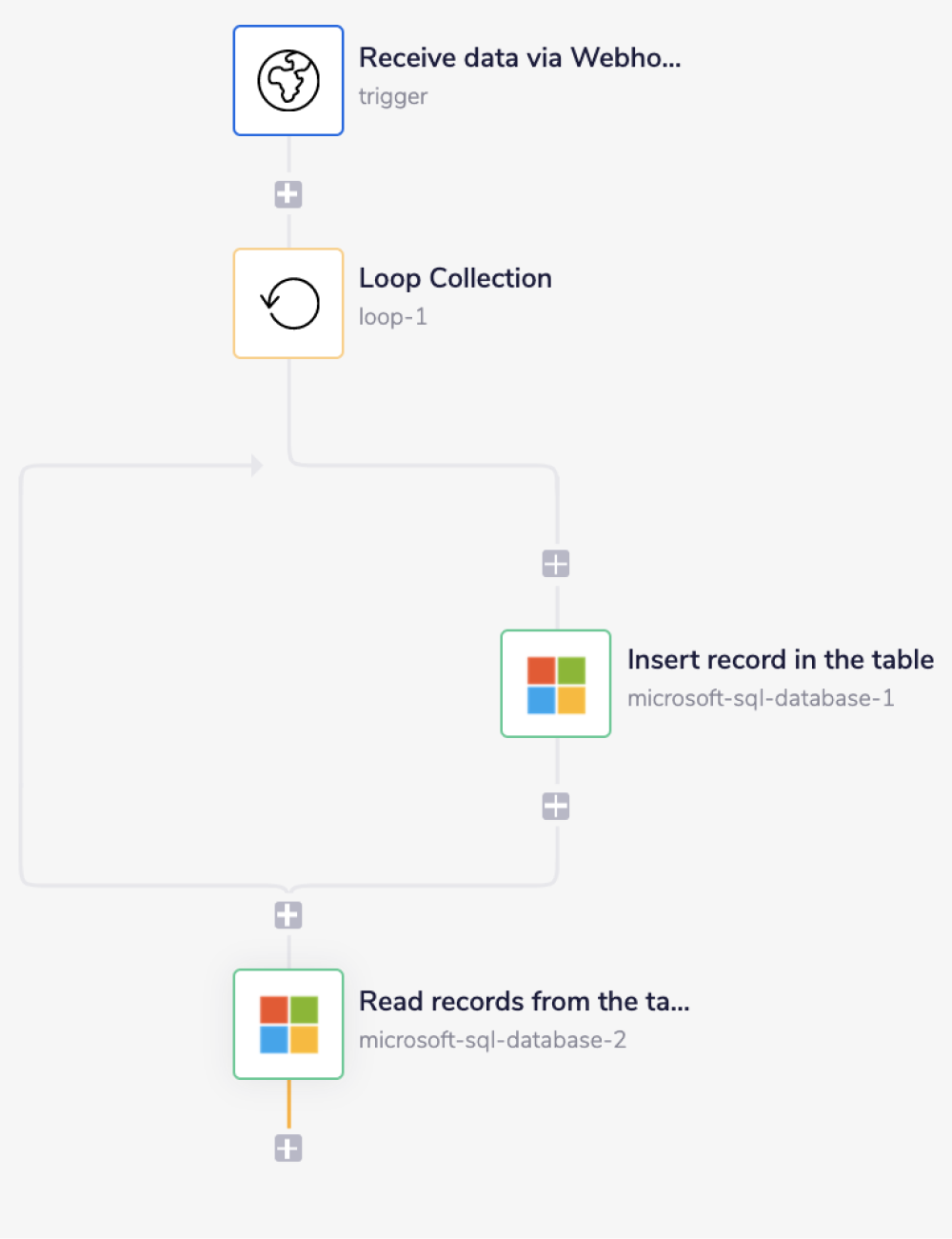
1 - Pull recordsCopy
When using a Webhook trigger, 'When webhook is received, auto respond with HTTP 200' is the most common operation unless you specify a custom response.
Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
In this example, the records received by the Webhook are in JSON format:
1[2{3"data": {4"id": "6012fe453f38ecab86530e97",5"first_name": "Brooks",6"last_name": "Hendrix",7"phone": "+1 (990) 546-2598"8},9"meta": {10"event": "create",11"type": "prospect"12}13},14{15"data": {16"id": "6012fe454256655c4da94179",17"first_name": "Crane",18"last_name": "Lindsey",19"phone": "+1 (932) 505-2355"20},21"meta": {22"event": "create",23"type": "account"24}25},26{27"data": {28"id": "6012fe45c0d81c6f14a78c4d",29"first_name": "Blake",30"last_name": "Mosley",31"phone": "+1 (956) 577-2515"32},33"meta": {34"event": "update",35"type": "prospect"36}37},38{39"data": {40"id": "6012fe45fd903b3e38f8f5ef",41"first_name": "Francis",42"last_name": "Mcdowell",43"phone": "+1 (940) 447-2645"44},45"meta": {46"event": "update",47"type": "account"48}49},50{51"data": {52"id": "6012fe4509b4461450de082c",53"first_name": "Sue",54"last_name": "Wilkerson",55"phone": "+1 (905) 508-3504"56},57"meta": {58"event": "update",59"type": "prospect"60}61},62{63"data": {64"id": "6012fe45150b03d02a887d2b",65"first_name": "Berry",66"last_name": "Riggs",67"phone": "+1 (872) 460-3574"68},69"meta": {70"event": "update",71"type": "prospect"72}73},74{75"data": {76"id": "6012fe45c86ec53152c0adcd",77"first_name": "Ray",78"last_name": "Nichols",79"phone": "+1 (859) 492-3067"80},81"meta": {82"event": "update",83"type": "prospect"84}85},86{87"data": {88"id": "6012fe45dbfaabd167439bde",89"first_name": "Reeves",90"last_name": "Carrillo",91"phone": "+1 (834) 541-2561"92},93"meta": {94"event": "update",95"type": "account"96}97}98]
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Webform, etc., will have different results / views.
2 - Add recordsCopy
Add a Loop connector with the 'List' field set to $.steps.trigger.body. You can use the connector-snake to generate this automatically.
JSONPATHS: For more information on what jsonpaths are and how to use jsonpaths with Tray.io, please see our pages on Basic data concepts and Mapping data between steps
CONNECTOR-SNAKE: The simplest and easiest way to generate your jsonpaths is to use our feature called the Connector-snake. Please see the main page for more details.

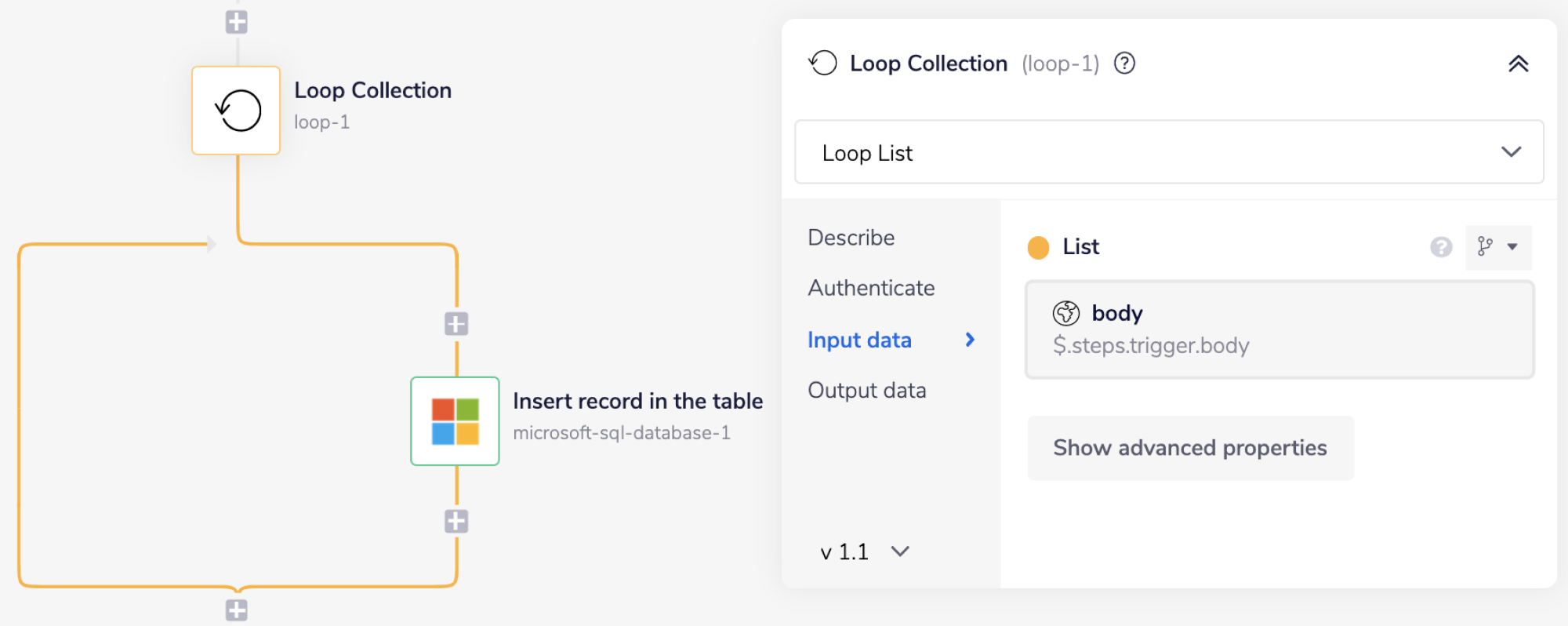
Next, add a Microsoft SQL database connector inside the Loop connector and set the operation to 'Insert rows'.
In the 'Rows to insert' field, add all the property names using the 'Add to Rows to insert' button for the selected table.
Select 'Column name' from the available drop-down options.

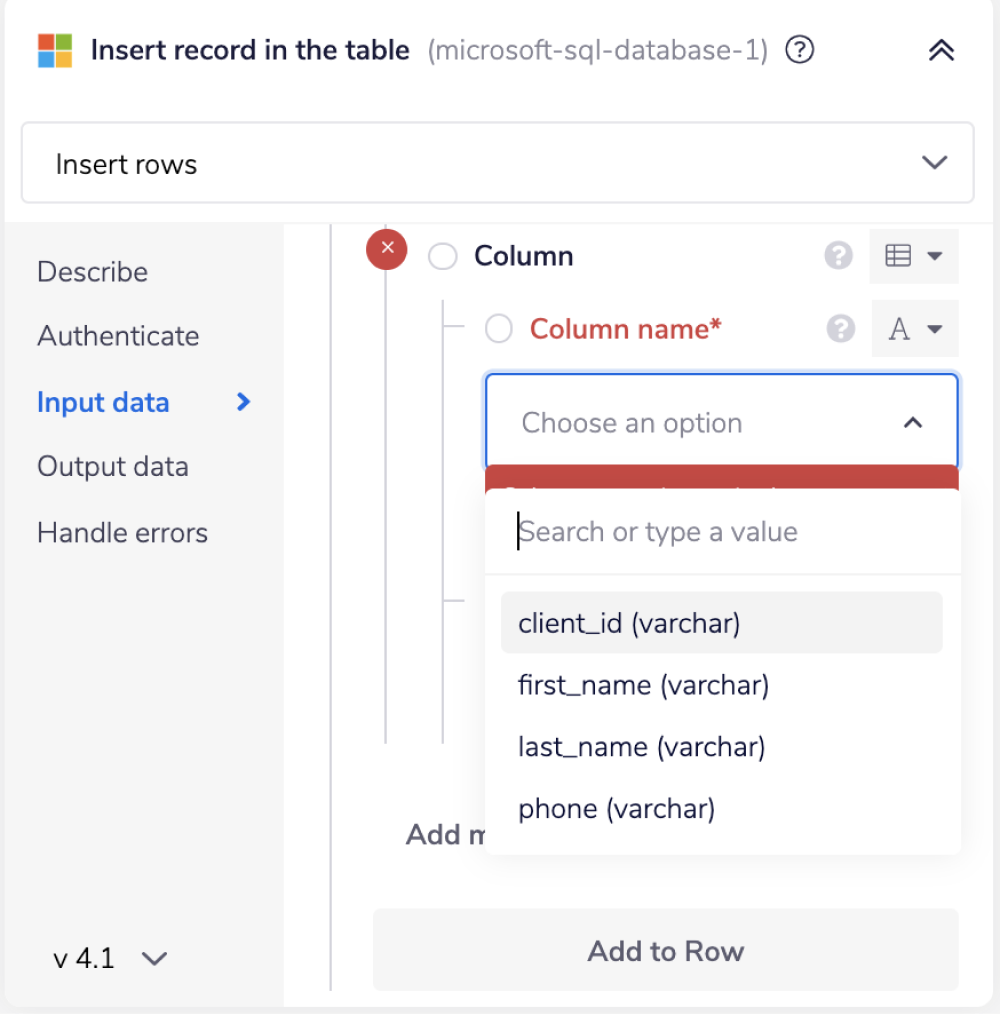
Using the connector-snake once more, find the jsonpath for each field from the previous step.

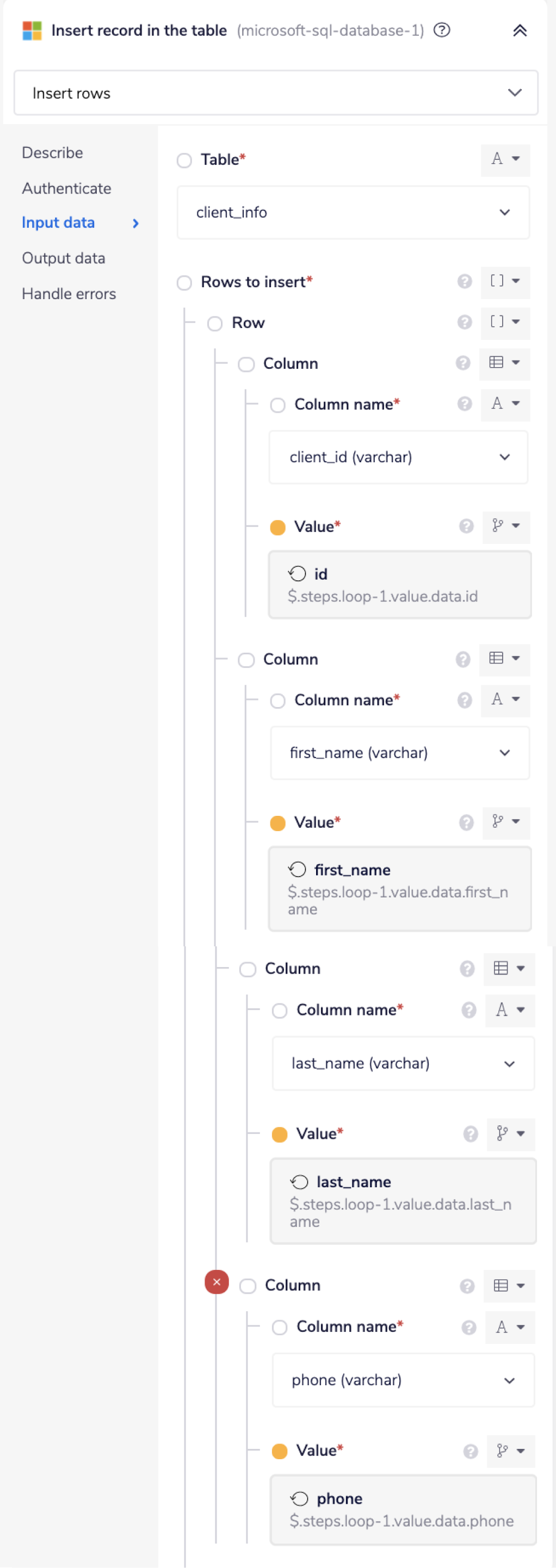
3 - Read recordsCopy
Add another Microsoft SQL database connector and set the operation as 'Run SQL query'.
Add the following query in the 'SQL query' field:
select * from client_info
The above query will list all the newly inserted rows in the previous step.

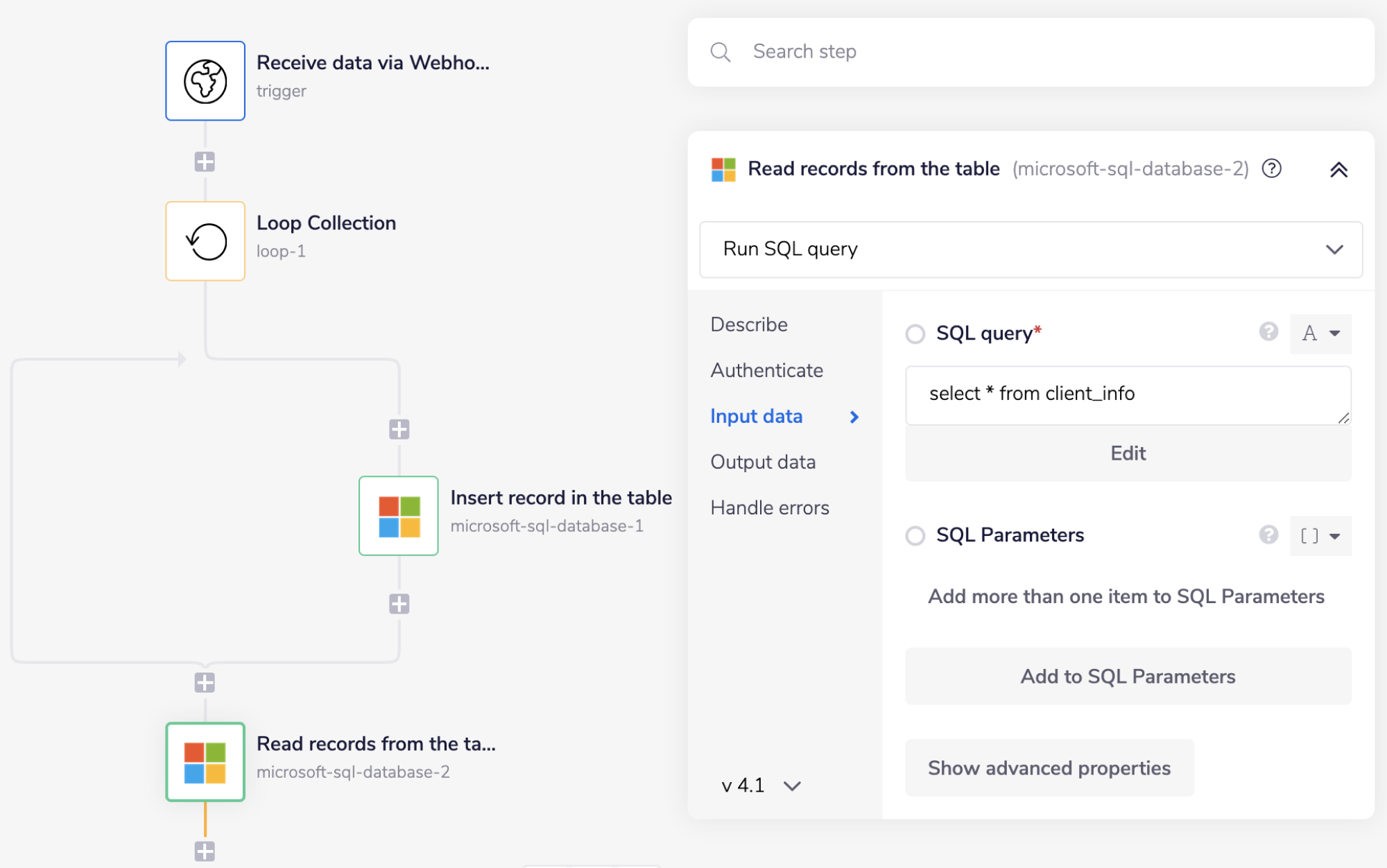
The fetched records in the final step should look similar to this:


Adding a record to a particular tableCopy
This workflow demonstrates how to insert records into multiple Microsoft SQL database tables based on the received data.
The Microsoft SQL database considered in this example contains three tables, namely 'account', 'prospect', and 'sequenceState'. So depending on the tableName specified in the received data, the workflow will add the data to the specified table.
The steps will be as follows:
Pull the records from the source (a webhook trigger in this example) and extract the table name from the value of the tableName attribute.
Navigate the course of the workflow to the appropriate branch using the Branch connector based on the value (table name) received from the previous step.
Insert the new records into the appropriate Microsoft SQL database table.
The final outcome should look like this:

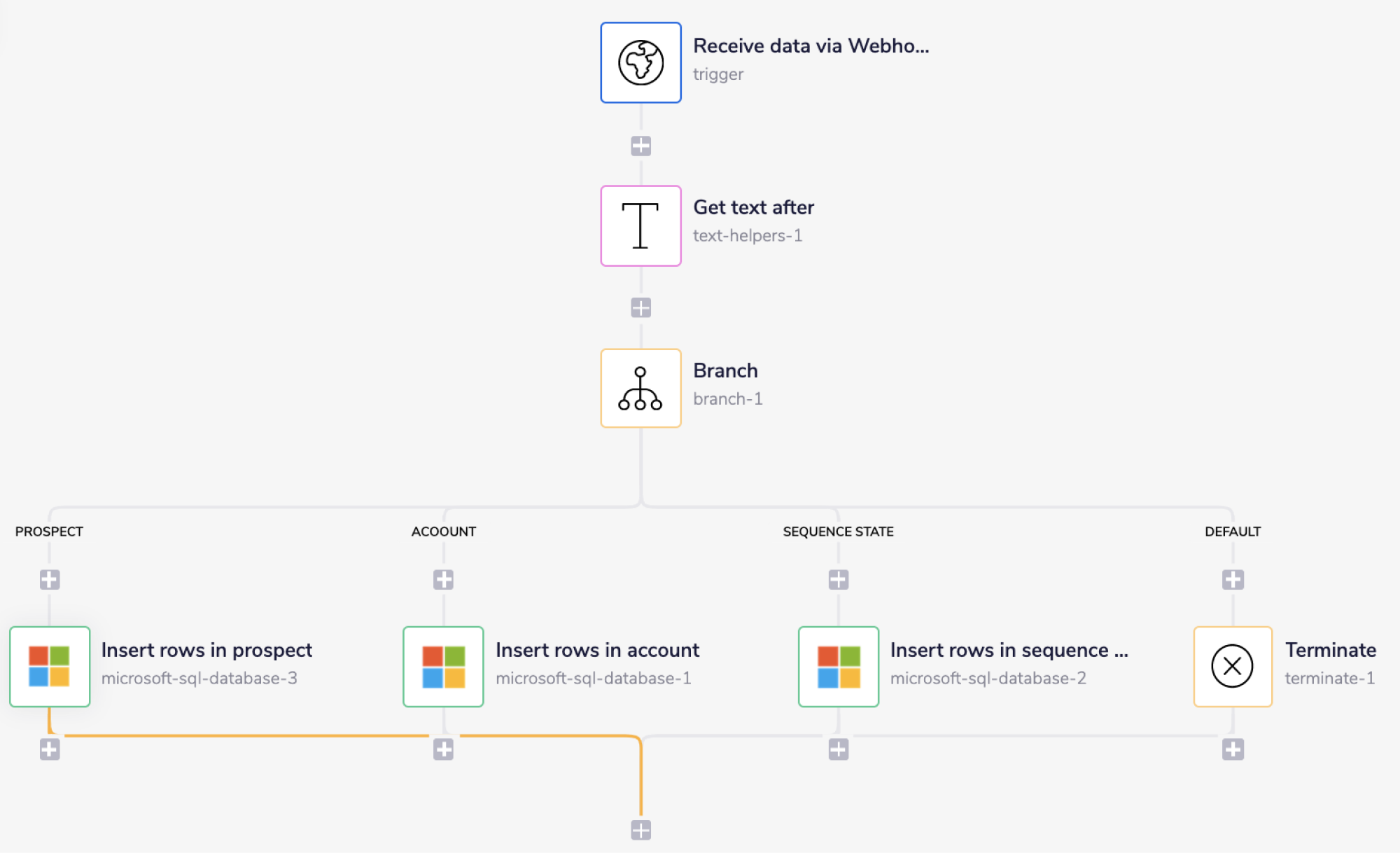
1 - Pull records and extract the table nameCopy
When using a Webhook trigger 'When webhook is received, auto respond with HTTP 200' is the most common operation unless you specify a custom response. Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
The records received by the Webhook are in JSON format:
1{2"data": [3[{4"field": "id",5"value": "20"6},7{8"field": "first_name",9"value": "Blake"10},11{12"field": "last_name",13"value": "Mosley"14},15{16"field": "phone",17"value": "+1 (956) 577-2515"18}19]20],21"meta": {22"tableName": "create.prospect"23}24}
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Outreach, etc., will have different results/views.
Next, add the Text Helper connector and set the operation to 'Get text after'.
The Text Helper connector using the 'Get text after' operation returns a substring based on the inputs provided.
As you can see in the image below, given a jsonpath to the 'String' field using the connector-snake ($.steps.trigger.body.meta.tableName) and a value to the 'Pattern' field as create.. It returns the substring between where the pattern was found depending on the 'Match number' 2 and the beginning of the string.

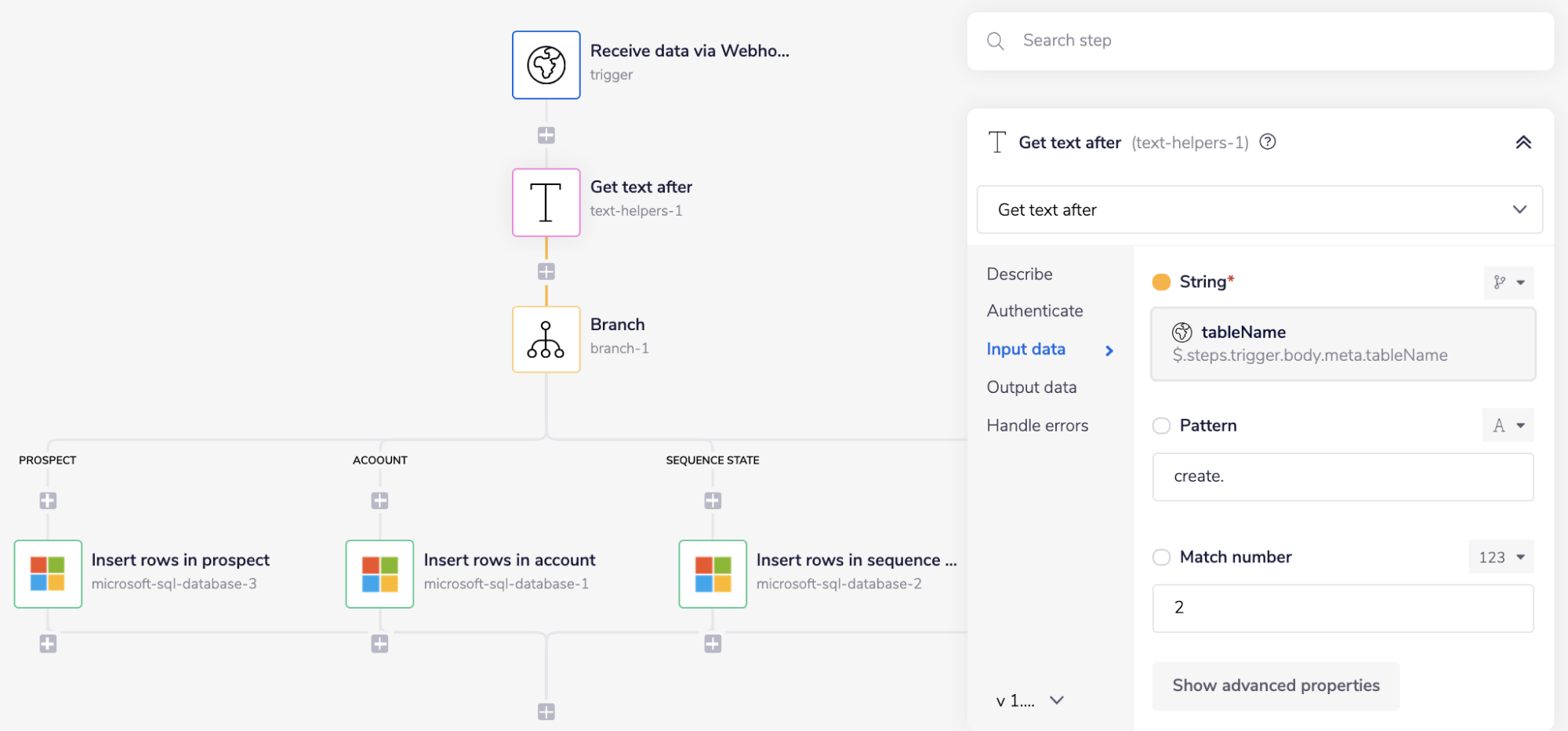
To understand this operation, consider the example JSON provided above. Based on the provided jsonpath and values for each field, the retrieved values are:
String:
create.prospectPattern:
create.Match number:
2
So when the values of the String and Pattern fields are compared, the match found is create.. So the operation provides the substring that comes after(second) the match. In this case, as you can see in the image below, the substring returned by the operation is prospect.

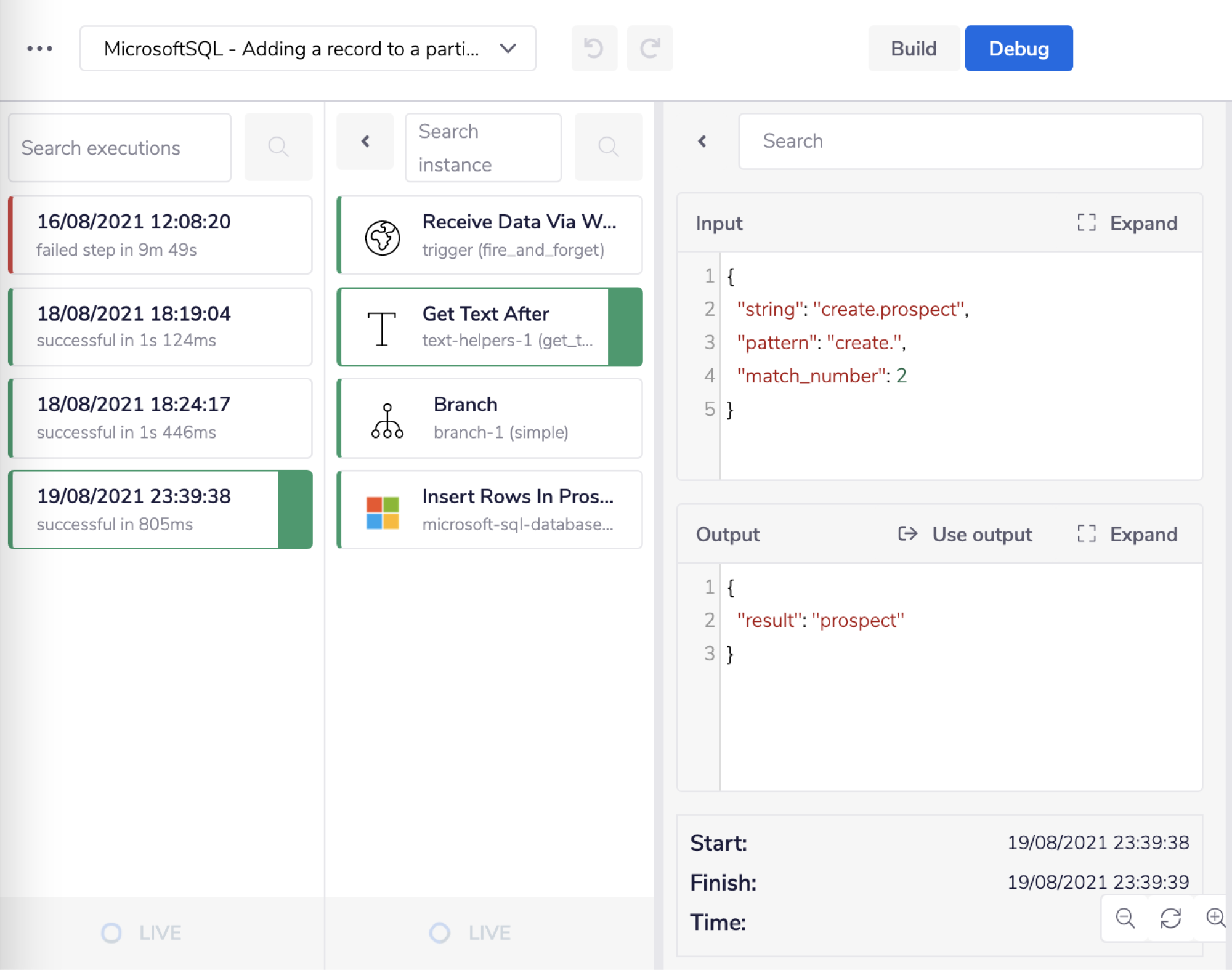
Based on this step's output, the workflow will navigate to the branch with the Label as 'Prospect'.
For more clarification on the pathways, you have available, open the Debug panel to view your step's Input and Output.
2 - Navigate and add recordsCopy
Add a Branch connector with the 'Value To Test' field set to $.steps.text-helpers-1.result. You can use the connector-snake to generate this automatically.
Set the 'Value' and 'Label' pair for each branch with the Microsoft SQL database table names, as shown in the image below.


The Branch connector will navigate the workflow execution based on the input received from the previous step. The possible values you could receive from the previous step are 'prospect', 'account', and 'sequenceState', thus the three branches.
The third branch is an auto-generated 'Default' branch, which will terminate the workflow if the branch does not receive any of the three values mentioned above as an input.
For the workflow to terminate, add the Terminate connector under this fourth branch, i.e., the 'DEFAULT' branch.
Next, add the Microsoft SQL database connector under each branch except the 'DEFAULT' branch, and set the operation to 'Insert new rows'.
As you can see, the 'Table' and the 'Rows to insert' fields are mandatory.
Select the appropriate table name from the drop-down options based on the branch your Microsoft SQL database connector is on. As you can see we have selected the table name for the first branch as prospect.
Using a connector-snake find the jsonpath for the 'Row' field from the Trigger step. It should appear similar to this: $.steps.trigger.body.data.

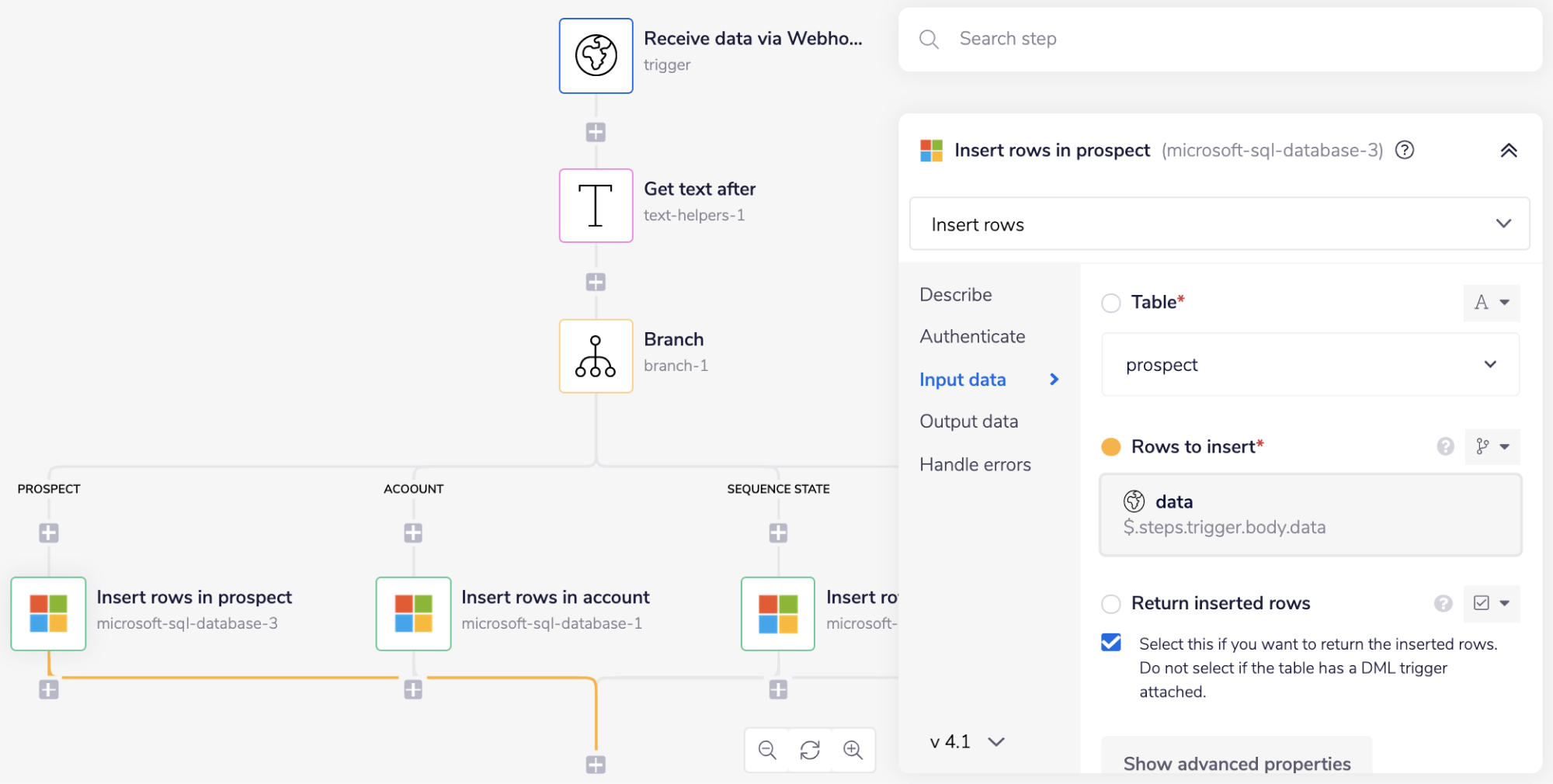
Similarly, add values for the 'Table' and the 'Rows to insert' fields for the Microsoft SQL database connectors under the 'ACCOUNT' and 'SEQUENCE STATE' branches.
The Insert new rows operation will insert the records received through the Webhook trigger in the selected Microsoft SQL database table.
Add or update recordCopy
The below example demonstrates how you could potentially use the Microsoft SQL database connector to insert and update the records into the Microsoft SQL database.
In this workflow, the record to be uploaded to the Microsoft SQL database is received through the Webhook trigger. The received record includes the event attribute which specifies if the record is to be created or updated.
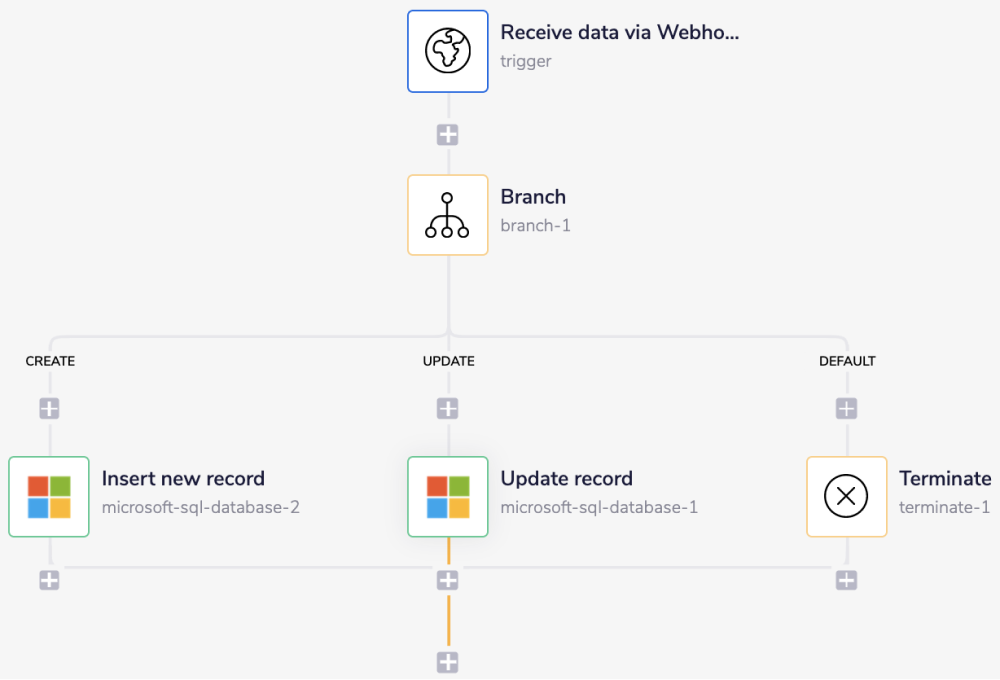
The steps will be as follows:
Pull the records from the source (a webhook trigger in this example) and navigate the course of the workflow to the appropriate branch using the Branch connector based on the value (event) received from the previous step.
Insert or update the record to the Microsoft SQL database.
The final outcome should look like this:

1 - Pull records and navigateCopy
When using a Webhook trigger 'When webhook is received, auto respond with HTTP 200' is the most common operation unless you specify a custom response. Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
Be sure to click the 'Enable' button before continuing. This makes the workflow ready to receive incoming calls.
The records received by the Webhook are in JSON format:
1{2"data": {3"id": "20",4"first_name": "Blake",5"last_name": "Mosleys",6"phone": "+1 (956) 577-2515"7},8"meta": {9"event": "update"10}11}
Remember that the format in which you receive data will vary depending on where it is coming from - pulling records from Salesforce, Outreach, etc., will have different results/views.
Next, add the Branch connector with the 'Value To Test' field set to $.steps.trigger.body.meta.event. You can use the connector-snake to generate this automatically.
Set the 'Value' and 'Label' pair for the first two branches as 'create' and 'update' as shown in the image below.

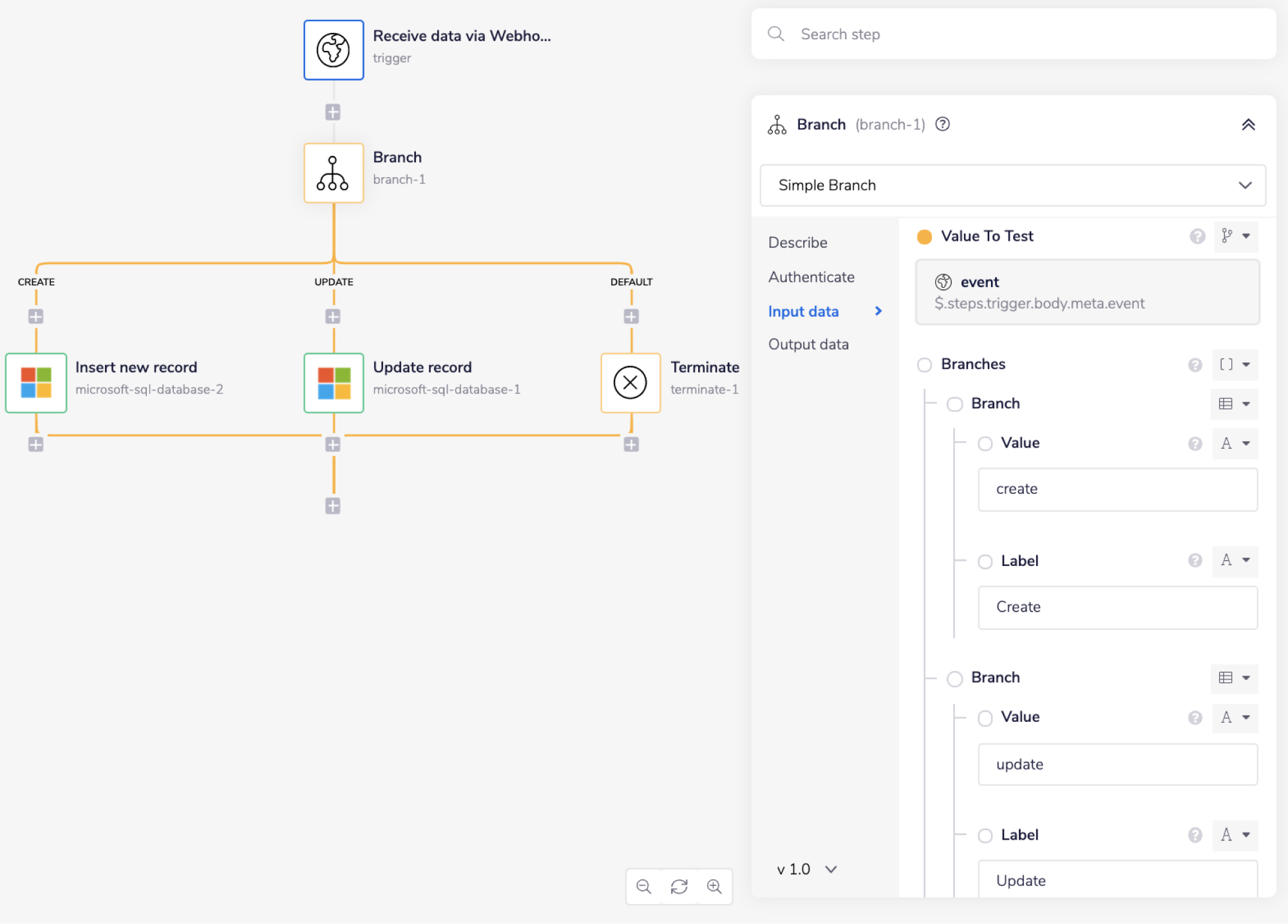
The Branch connector will navigate the workflow execution based on the value of the event attribute received in the JSON data from the trigger. The possible values you could receive are 'create' and 'update', thus the first two branches.
The third branch is an auto-generated 'Default' branch, which will terminate the workflow if the branch does not receive any of the two values mentioned above as an input.
For the workflow to terminate, add the Terminate connector under this fourth branch, i.e., the 'DEFAULT' branch.
2 - Insert or update the recordCopy
Now, add the Microsoft SQL database connector under each branch except the 'DEFAULT' branch.
As you can see in the image below, the first Microsoft SQL database connector under the 'CREATE' branch will insert a new record into the Microsoft SQL database. The second Microsoft SQL database connector under the 'UPDATE' branch will update the received record into the Microsoft SQL database.

The two Microsoft SQL database connectors for insert and update operation can be configured as follows:
Microsoft SQL database connector to insert a record:
To insert the record, set the operation to 'Insert new rows'.
As you can see, the 'Table' and the 'Rows to insert' fields are mandatory.
Select the table name of your choice from the available drop-down options. As you can see, in this example, we have selected the table name as customer_details.
Using a connector-snake find the jsonpath for the 'Row' field from the Trigger step. It should appear similar to this: $.steps.trigger.body.data.

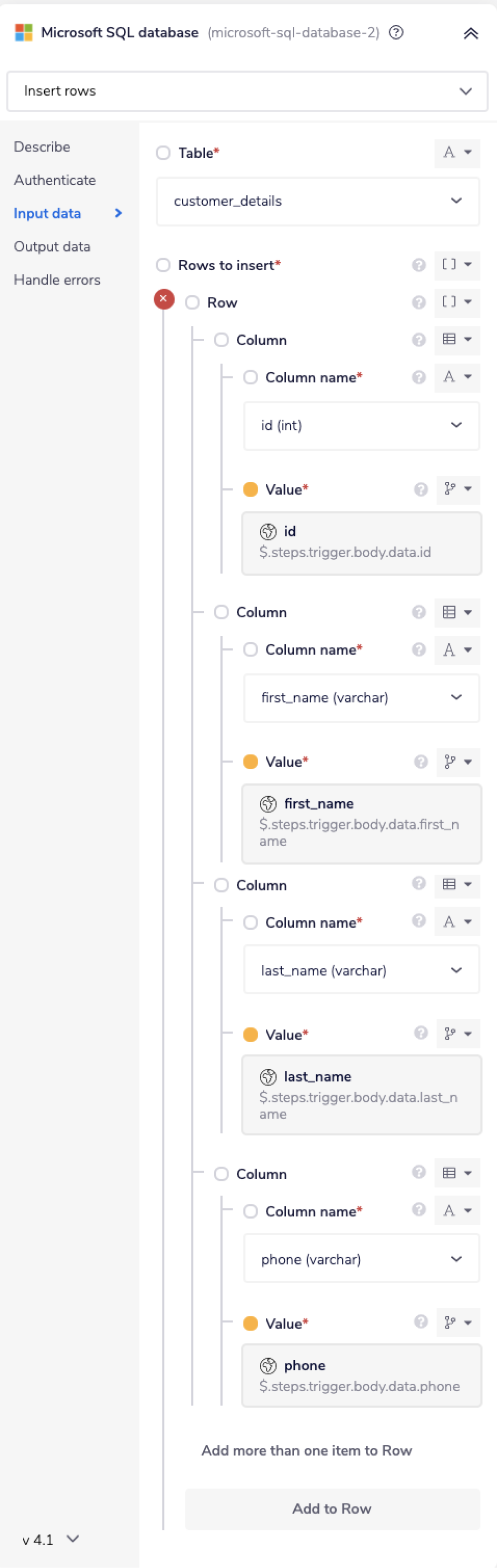
Now, based on the selected table and the jsonpath for the received data, the workflow will insert the received record into the selected Microsoft SQL database table.
Microsoft SQL database connector to update a record:
To update the record, set the operation to 'Update rows'.
Set the values for the 'Table' and the 'Rows to insert' fields similarly as we did above.
Before updating the record, the Update rows operation matches the existing 'id' from the selected Microsoft SQL database table with the ID of the data received from the trigger: $.steps.trigger.body.data.id.
Thus, as you can see in the image below, the condition is set to specify the id of the existing record that needs to be updated.


Now, based on the specified table, jsonpath, and the condition, the workflow will locate and update the record if it already exists.
Managing DataCopy
Batch insertion of dataCopy
For efficiency purposes, and to reduce the amount of calls you make to Microsoft SQL database, you want to avoid a situation where you are looping through data and inserting it row by row, such as the following:


The following workflow shows a simple example of how you can loop through batches of e.g. 200 records so that you can make e.g. 10 calls of 200 instead of 2000 individual calls.
Exactly how you will do this will depend on the service you are pulling records from

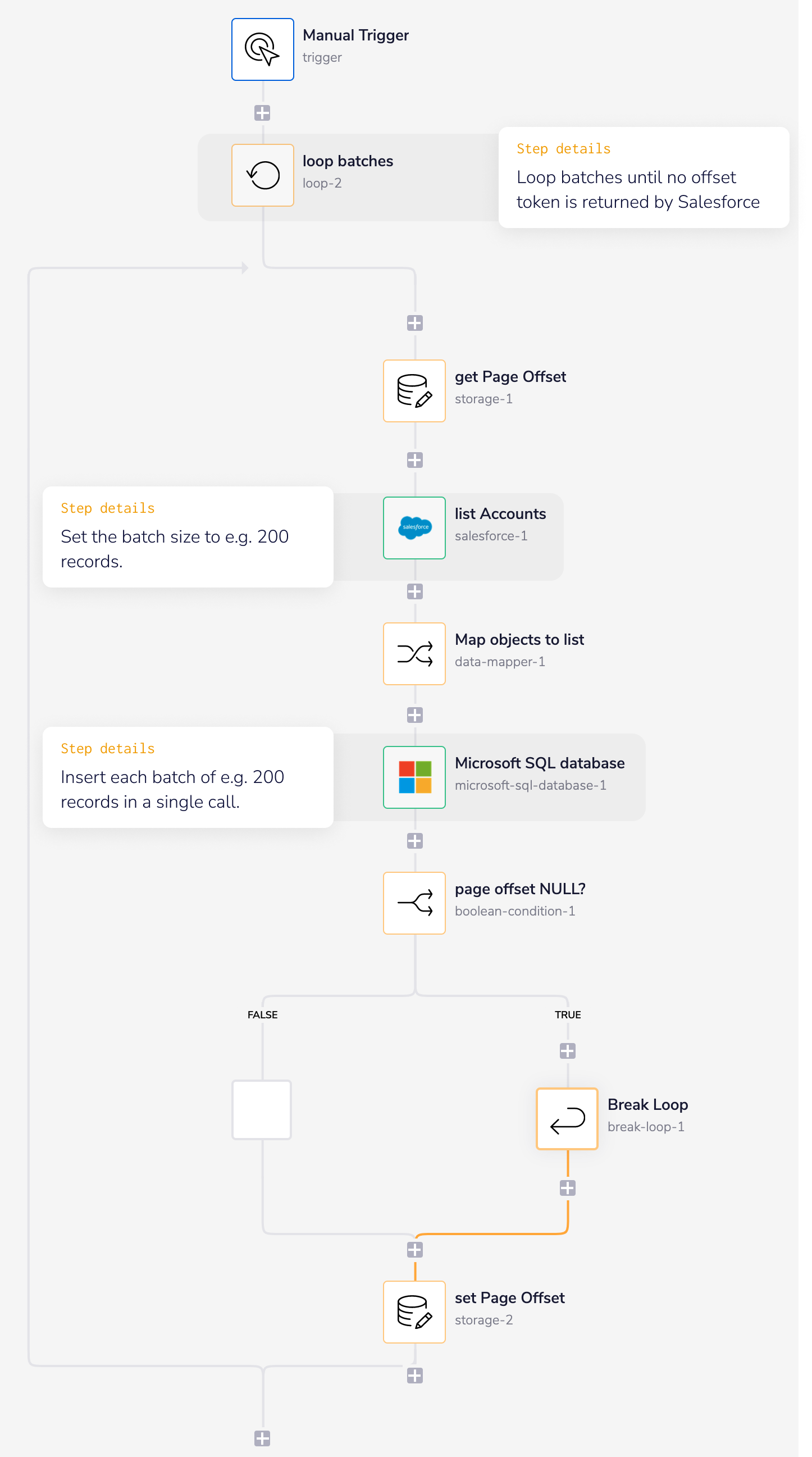
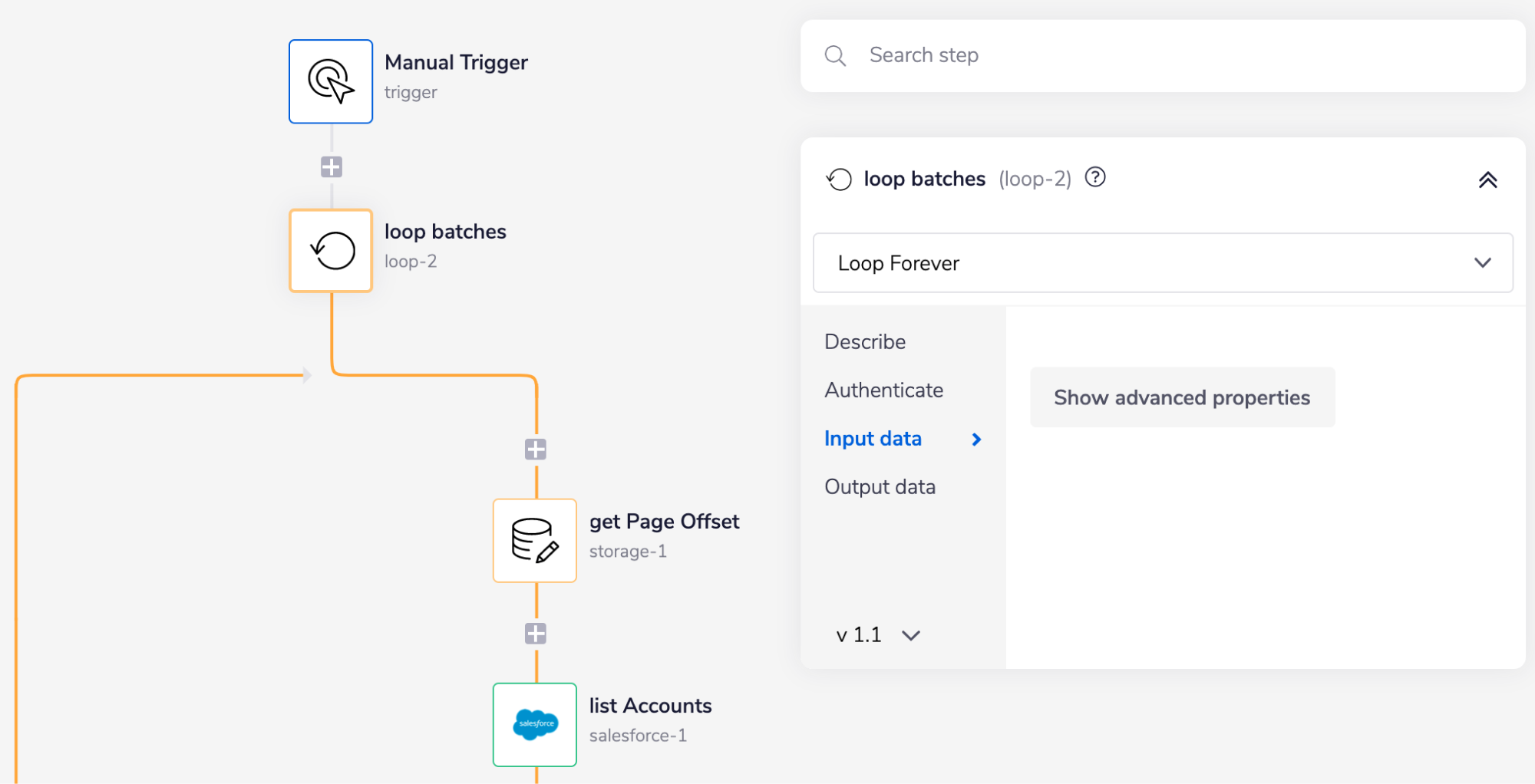
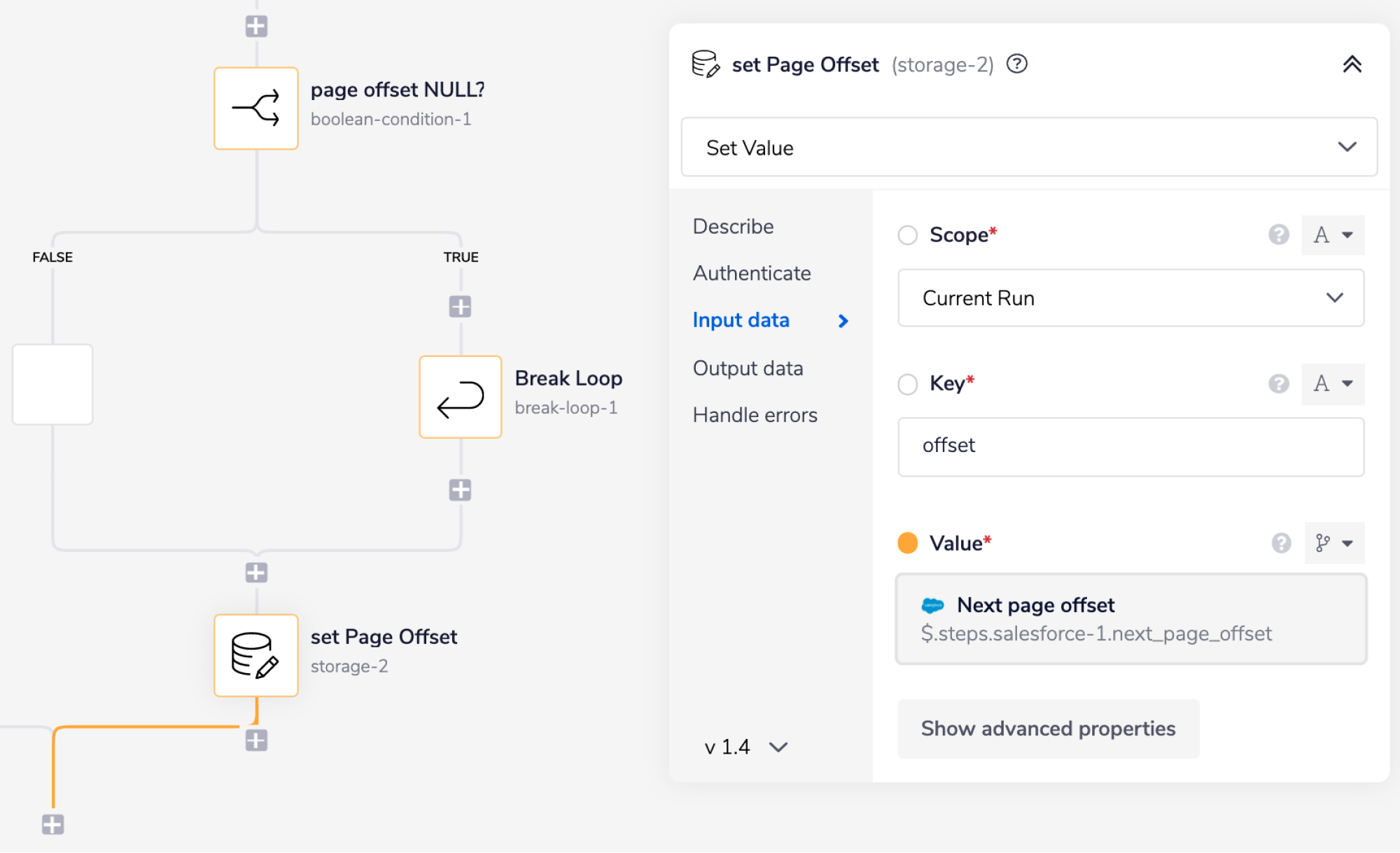
Loop batches is the main loop which is set to 'loop forever' and keeps running until Salesforce doesn't return an offset token - indicating there are no more batches to loop through.

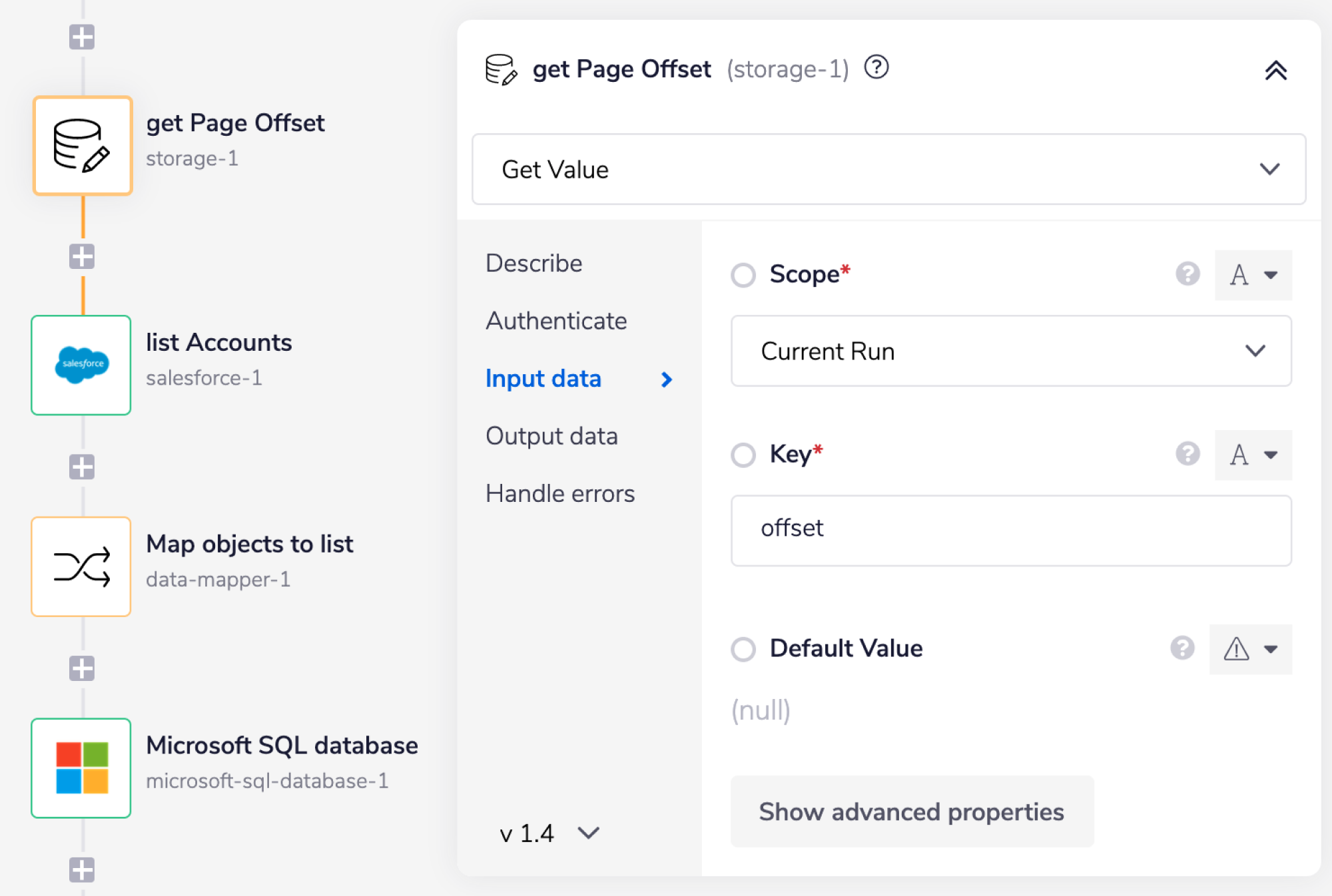
get page offset gets the offset token returned by Salesforce in the previous loop, so that Salesforce knows where to start retrieving this batch of records.

list accounts specifies what record type and fields to retrieve from Salesforce.

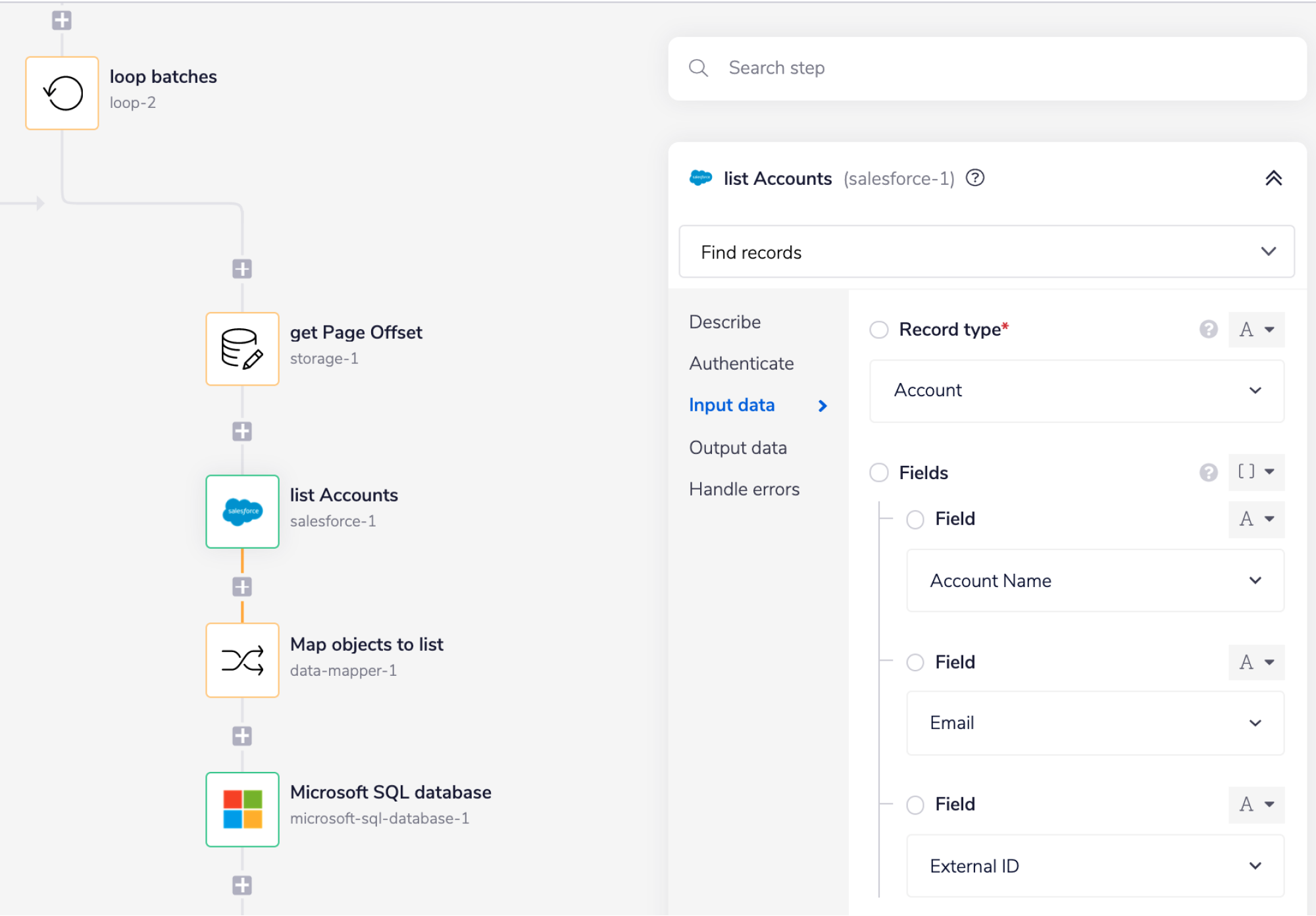
It also passes the page offset token, and sets the batch size.

USER TIP: If necessary you can always transform the extracted data before you load it into your database. Transformation could be anything such as formatting the data or changing the data type to match the accepted database format. To learn more, please see our ETL documentation
Records received from Salesforce looks like this:


Map objects to list is a data mapper step that maps an array of objects, i.e., records received from the previous step into an array of key-value objects.
In order to insert records in a single call into the Microsoft SQL database, the records should be an array of key-value objects.

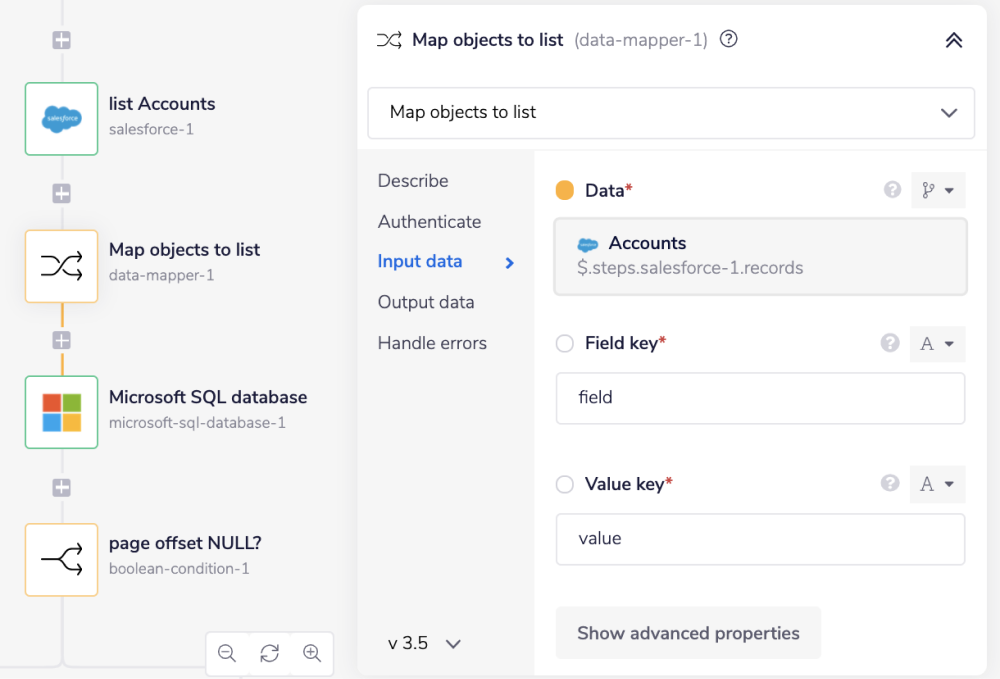
The output for the data mapper should look similar to this:


Insert rows then inserts the data from the current list into the selected Microsoft SQL database table in a single call.

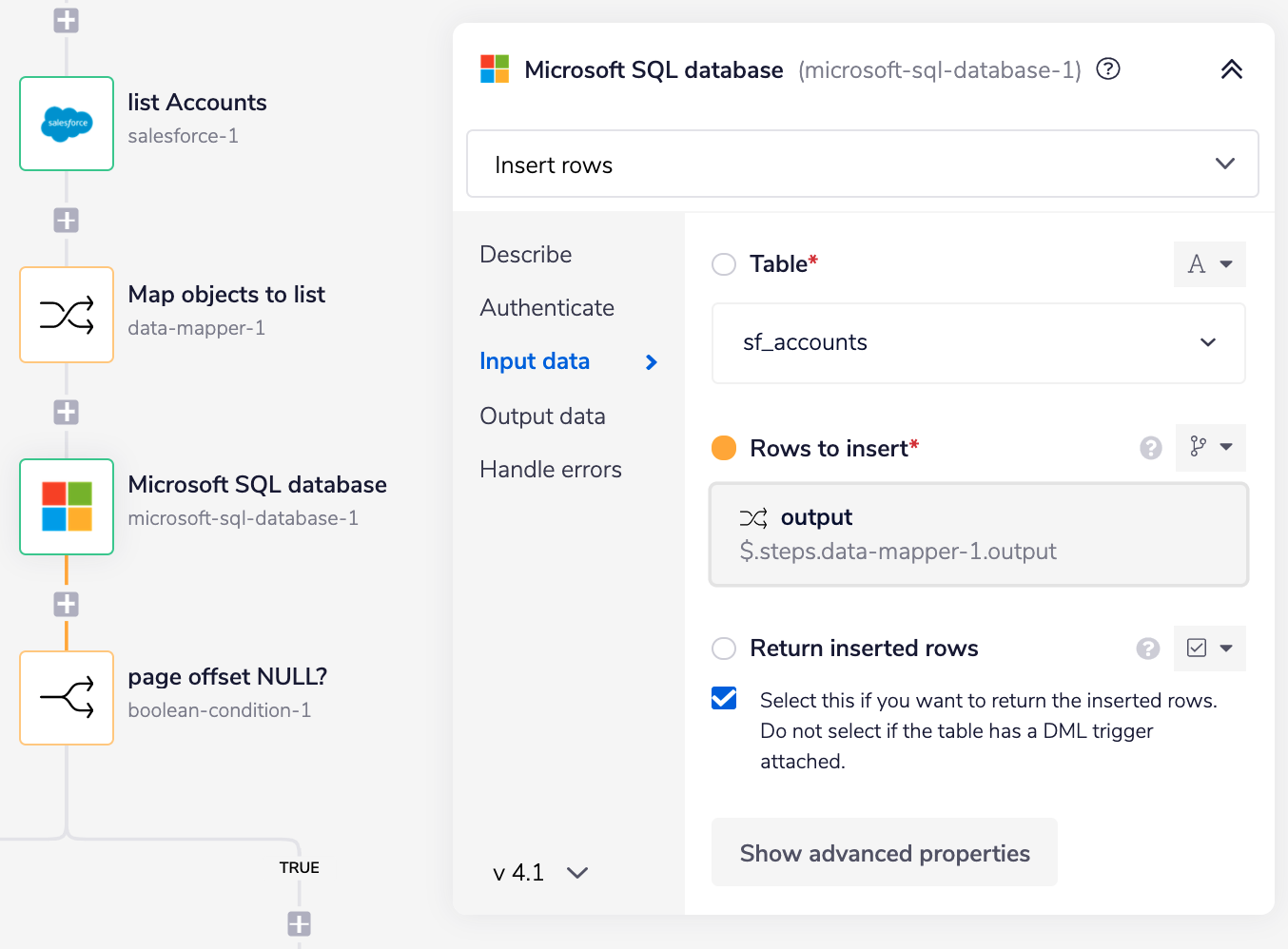
The payload sent to the Microsoft SQL database is an array of key-value objects received from the Map objects to list step, which matches the format accepted by the Microsoft SQL database to insert the data in a single call.
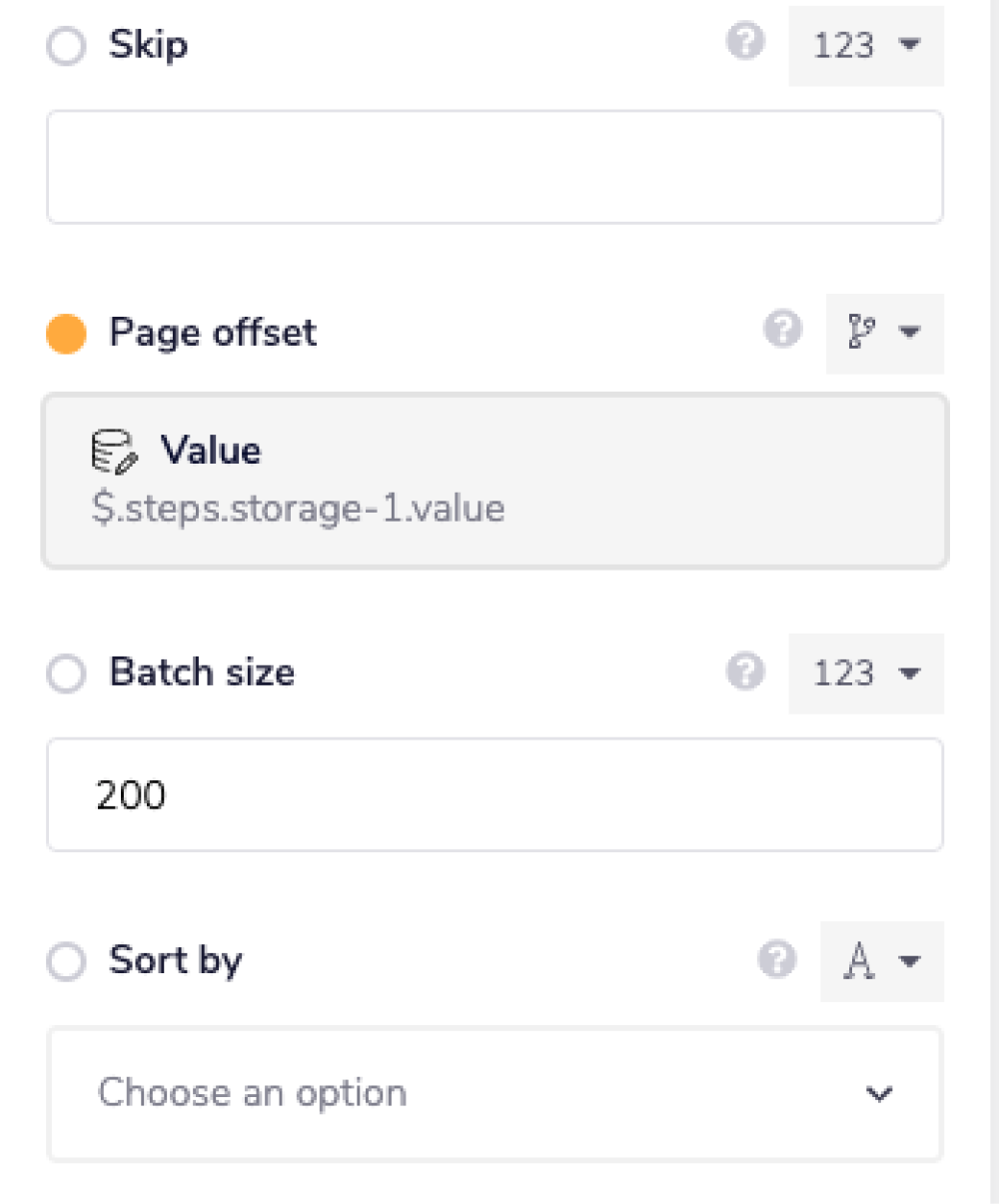
page offset NULL? uses
$.steps.salesforce-1.next_page_offsetto check if Salesforce has returned an offset token to indicate more batches are to be processed. If not, then the main loopbatches loop is broken.set page offset then stores the offset token to be retrieved at the start of the next batch.

Processing dynamic dataCopy
Sometimes, depending on the data source, your workflow may receive dynamic data payloads - i.e., the attributes within may vary for each execution of your workflow.
Let's assume an example where you wish to insert some data into a Microsoft SQL database.
The data that you have received for the first execution of your workflow is in this format:
1{2"data": {3"id": "129273",4"attributes": {5"department": "IT",6"branch": "London"7}8},9"meta": {10"deliveredAt": "2021-01-29T07:52:28.094+00:00"11}12}
For the second execution, your workflow may receive the data with more attributes like this:
1{2"data": {3"id": "129273",4"attributes": {5"department": "IT",6"branch": "London",7"country": "uk",8"zip": "JU59KL"9}10},11"meta": {12"deliveredAt": "2021-01-29T07:52:28.094+00:00"13}14}
PLEASE NOTE: It is essential that the attributes received in the JSON data correspond to the column names in your Microsoft SQL database table.
So in such a situation, where it is difficult to gauge the attributes you may receive in your data for each execution. We cannot map each attribute with their respective column names in order to upload the data in the Microsoft SQL database table, i.e., something like this, as shown in the image below, is not possible:
To understand the mapping of each attribute with the column name, please refer to the Insert records workflow explained above.
So as a solution, you have to upload the data in bulk, i.e., in one go. This is possible only if the received JSON data has a flat structure.
The best way to transform a nested JSON structure into a flat structure is by using a Data Mapper connector.
So the following workflow demonstrates how you could deal with dynamic data using a Data Mapper connector that flattens the nested JSON and uploads this data into your Microsoft SQL database table.
PLEASE NOTE: The Data Mapper connector, as explained in this workflow, can be used only with the dynamic data for which you know the possible list of attributes.
In this example, we show data being received via the Webhook trigger - i.e., a scenario whereby you have configured an external service to automatically send new record data to your Tray.io workflow.
In practice, you can receive data in any structure, and in other ways, such as from any pre-built Tray.io service trigger or from a previous workflow step which has pulled data from another source (e.g., Salesforce 'Find Records', CSV Reader, etc.)


The Webhook trigger with operation as 'Auto respond with HTTP 200' listens for the incoming data.
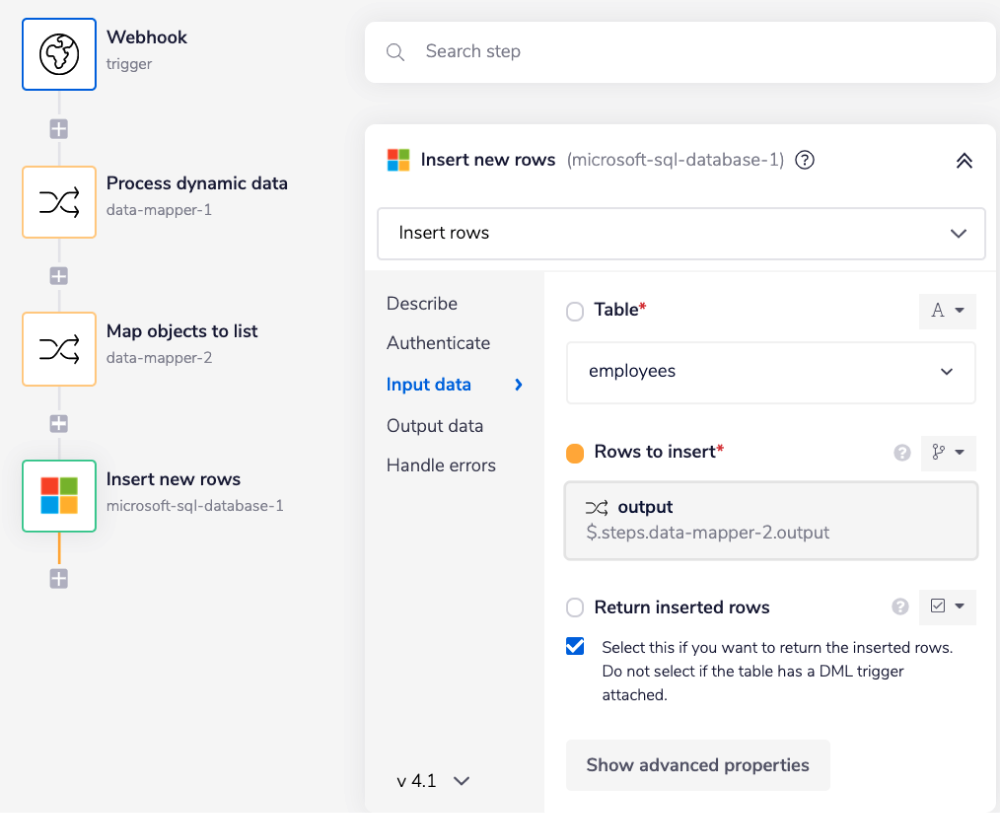
The Process dynamic data step is a Data Mapper connector step which flattens the received JSON data in order to handle the incoming dynamic data.
The 'Mapping' field transforms the nested structure i.e attributes.[column_name] to a flat structure, i.e. just the [column_name]. The 'Mapping' field contains a list of all the possible attributes that you wish to get a flat structure for.

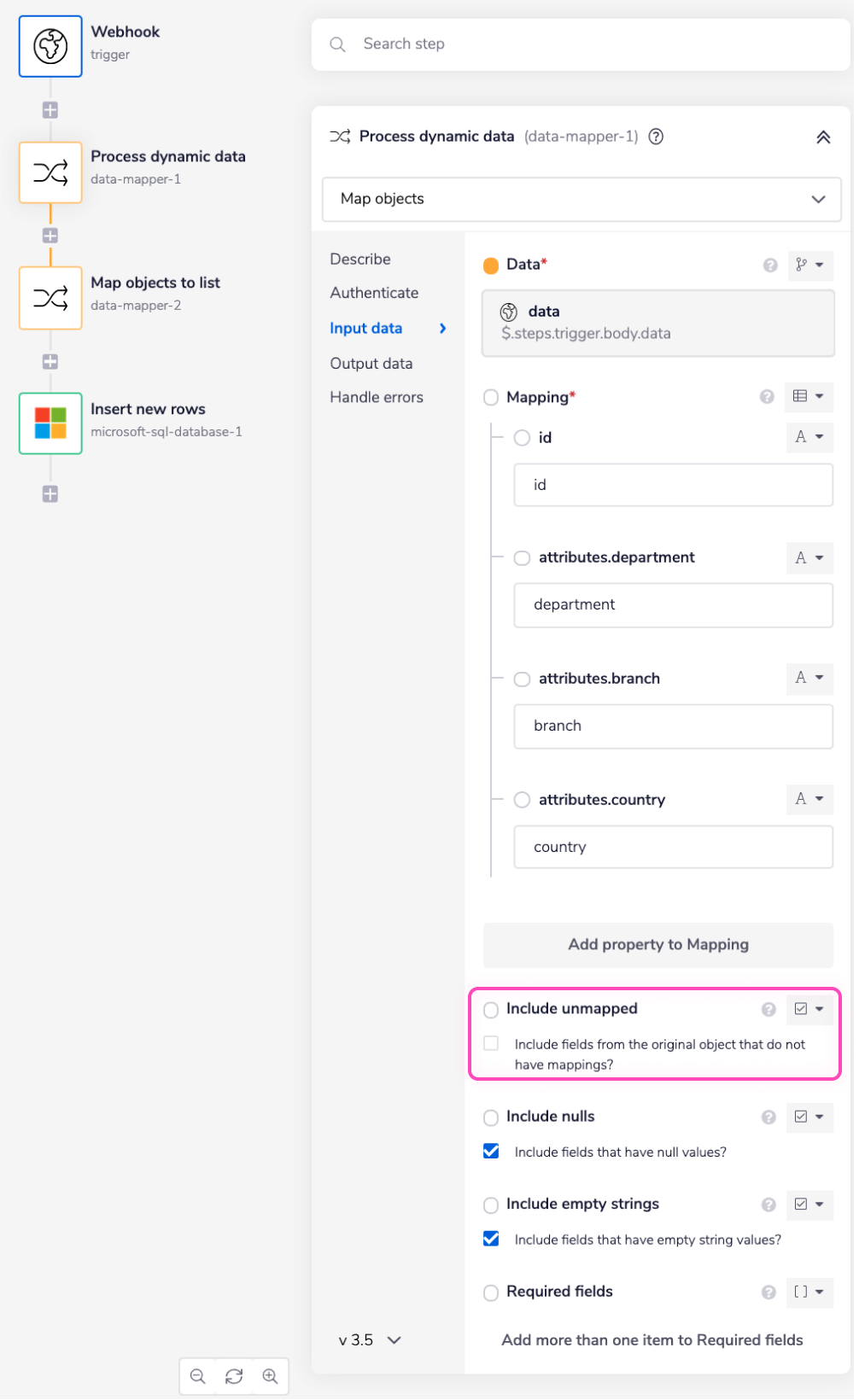
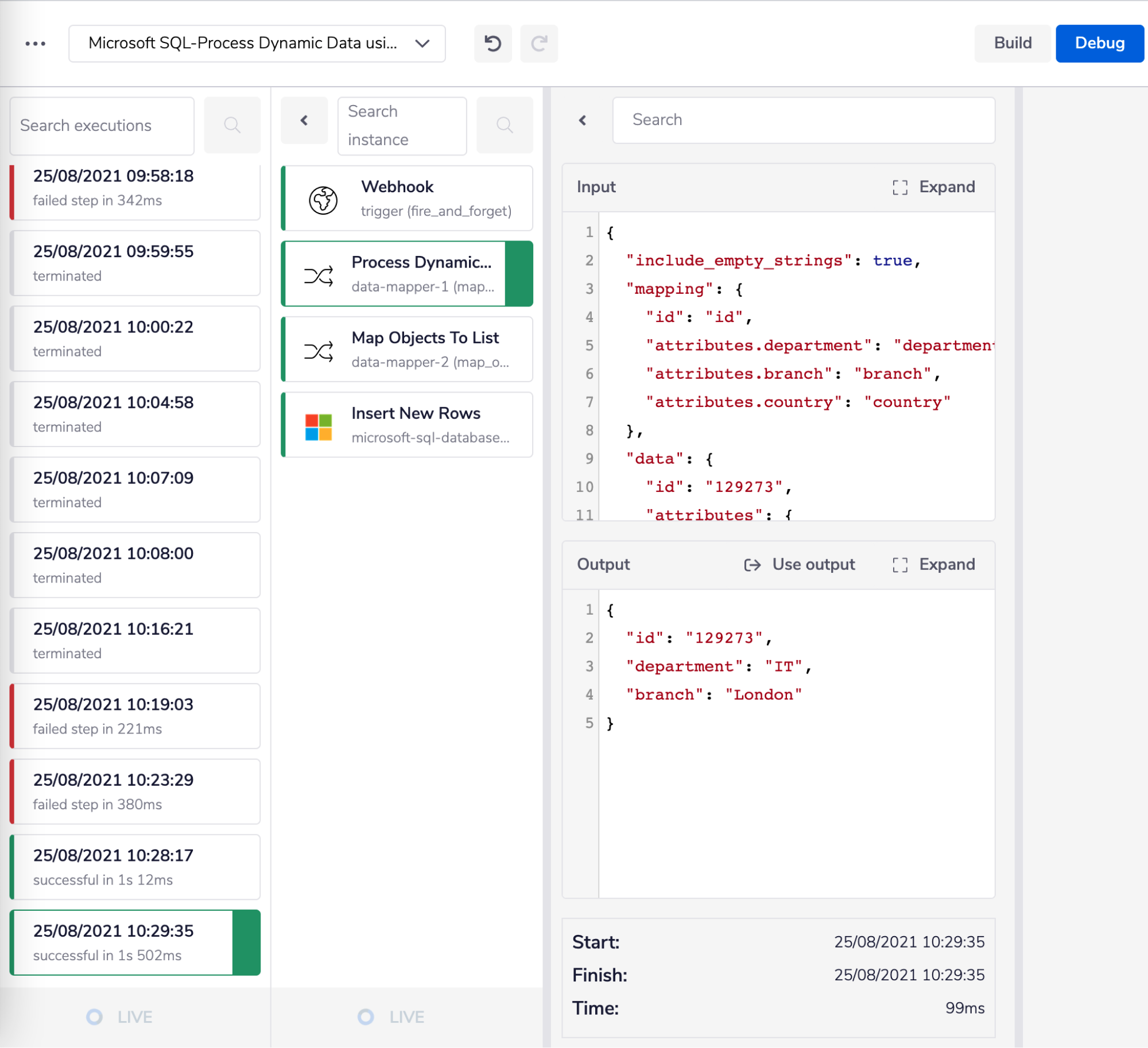
Make sure to uncheck the 'Included unmapped' field. If you do not uncheck this field, it will include the fileds from the received JSON data that you haven't listed in the Mappings field, i.e., something like this:


If the 'Included unmapped' field is unchecked the expected flat JSON output should look like this:

Map objects to list is a data mapper step that maps an array of objects, i.e., records received from the previous step
$.steps.data-mapper-1into an array of key-value objects.
In order to insert records in a single call into the Microsoft SQL database, the records should be an array of key-value objects.

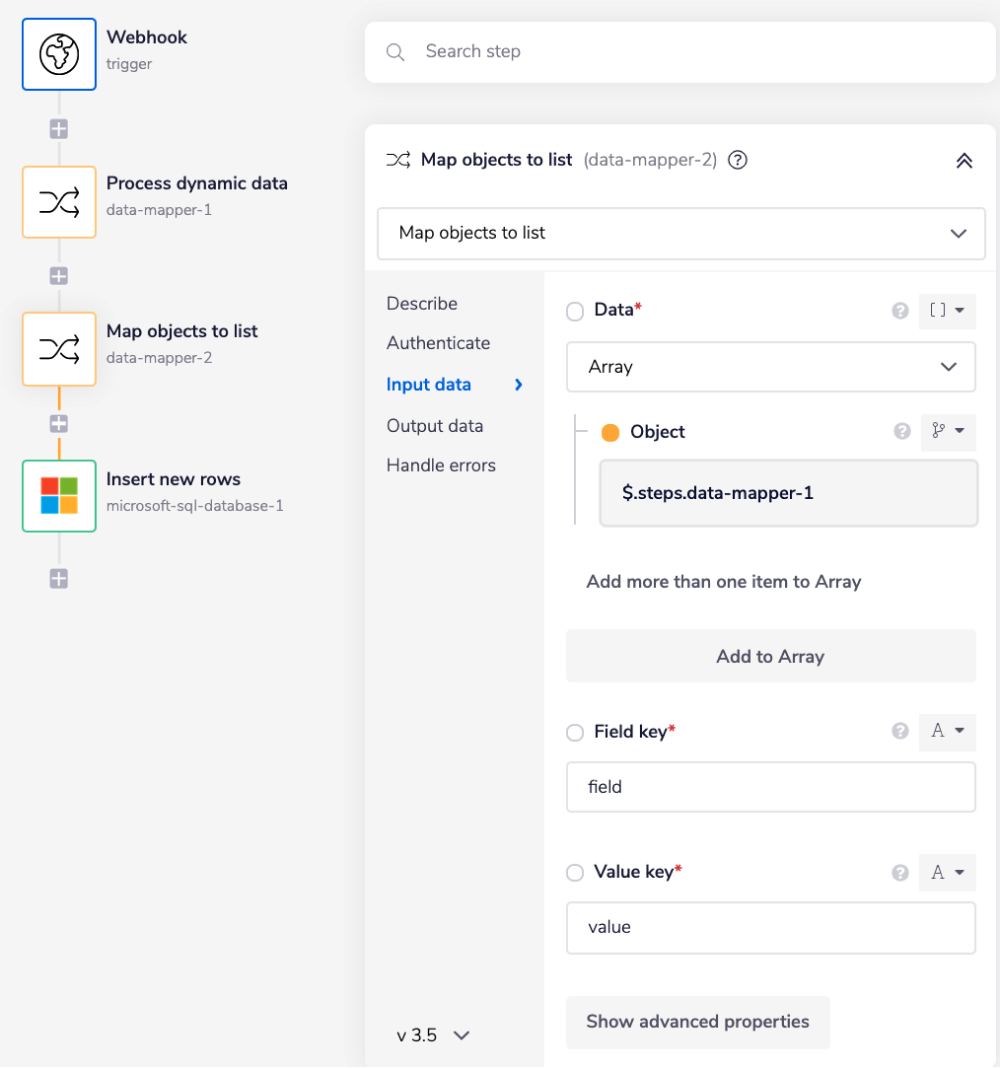
The output for the data mapper should look similar to this:


The Insert new rows step inserts an array of key-value objects (format accepted by Microsoft SQL database) received from the previous step in the selected Microsoft SQL database table.

BEST PRACTICES: Whenever you do decide to create your own workflow, be sure to check out some of our key articles such as: