
PDF Helpers 1.2
The PDF Helper is a collection of helpers to extract and convert data from PDF files
OverviewCopy
PDF helpers allows you to parse and analyses PDF documents. It provides features to extract raw data and interactive input fields and convert them to JSON object.
AuthenticationCopy
When the a PDF connector step is selected, in the properties panel on the right you will notice that no authentication is necessary. This is because it does not need to authenticate with an outside API service.
Available OperationsCopy
Convert PDF to JSON
Please see the Full Operations Reference for details on all available operations for this connector.
Note on Operations UsageCopy
API LIMITATIONS: Currently PDF parser doesn't support parsing of radio buttons. You still can successfully process other interactive fields and parse raw text content.
API LIMITATIONS: Since parsing of PDF files is a costly process, there is a limit for PDF document size to upload: 10MB
Example UsageCopy
This example will demonstrate how to upload PDF file a using 'Google Drive' and convert file content to JSON format.
TRAY POTENTIAL: Tray.io is extremely flexible. By design there is no fixed way of working with it - you can pull whatever data you need from other services and work with it using our core and helper connectors. This demo which follows shows only one possible way of working with Tray.io and the PDF Helpers connector. Once you've finished working through this example please see our Introduction to working with data and jsonpaths page and Data Guide for more details.
The steps will be as follows:
Setup using a manual trigger and Google Drive connector
Get List fils from Google Drive account
Download PDF File to parse
Convert chosen file to JSON
The final outcome should look like this:

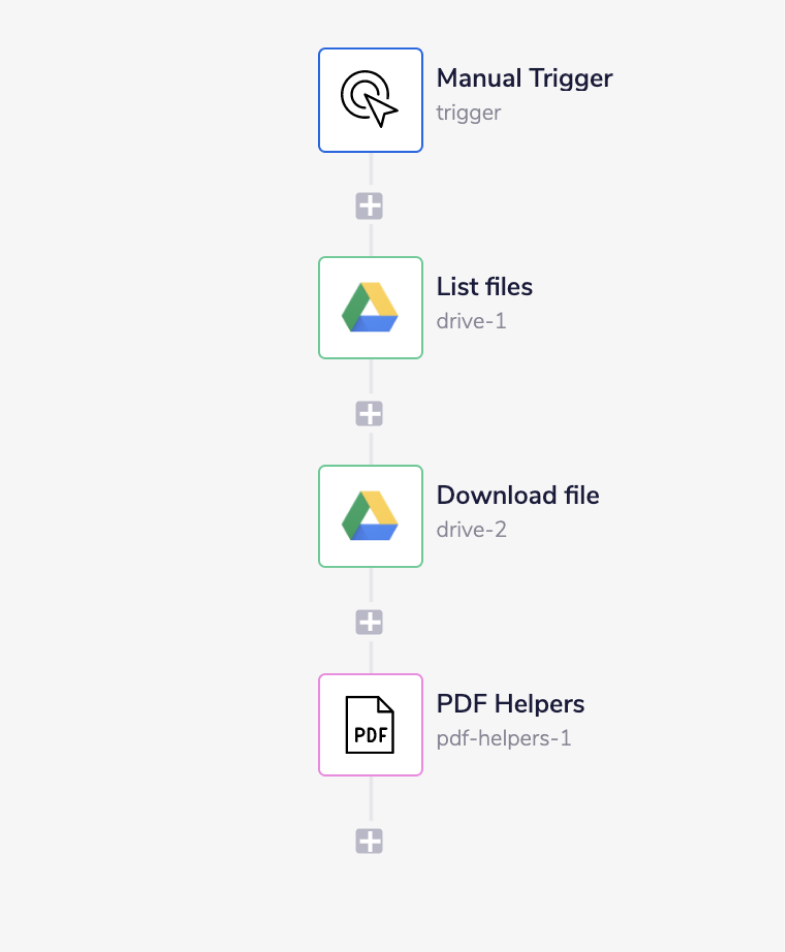
1 - Setup trigger & Google Drive connectorCopy
Once you have clicked 'Create new workflow' on your main Tray.io dashboard (and named said new workflow), select the Manual trigger from the trigger options available

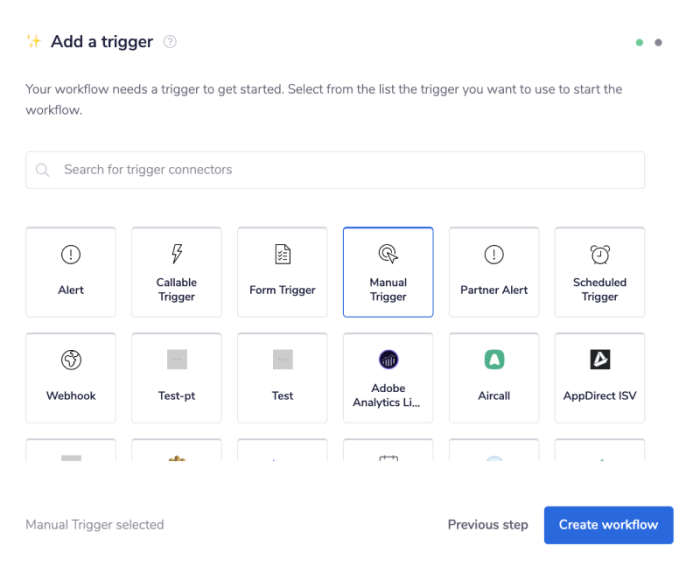
Once you have been redirected to the Tray.io workflow dashboard, from the connectors panel on the left, add a Google Drive connector to your second step. Set the operation to 'List files'.

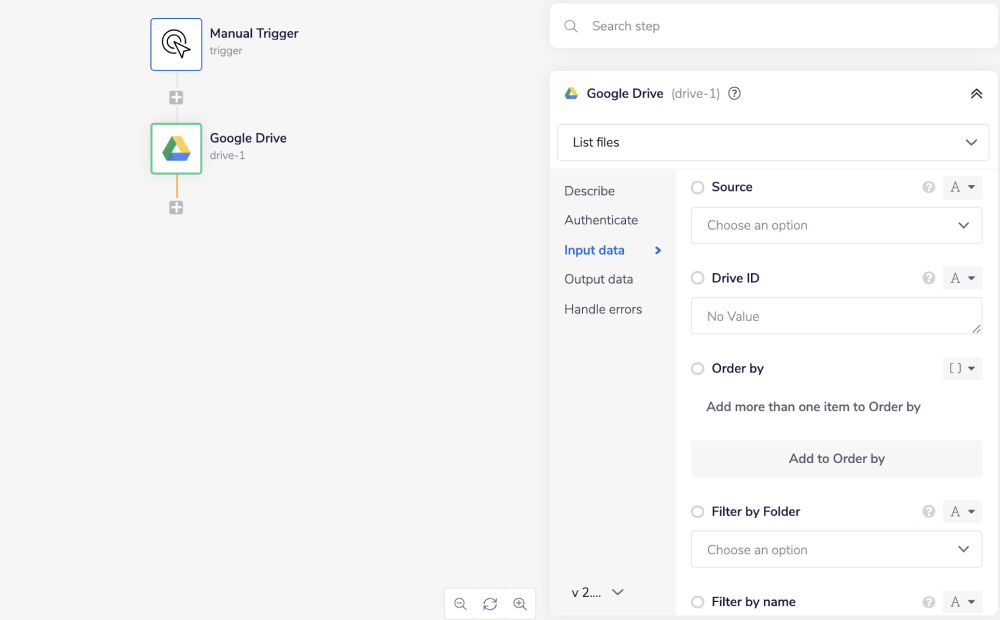
2 - Get List fils from Google Drive accountCopy
You will receive a paginated list of files available on your Google Drive. Find the one you want to convert. You can filter the results by name and folder
3 - Download PDF File to parseCopy
From the connectors panel on the left, add a Google Drive connector to your third step. Set the operation to 'Download file'. This operation requires File ID as an input parameter. You can copy ID from the 'List files' step or you can use the $.steps.drive-1.files[1].id to pull it from the first Google drive step.
JSONPATHS: For more information on what jsonpaths are and how to use jsonpaths with Tray.io, please see our pages on Basic data concepts and Mapping data between steps
CONNECTOR-SNAKE: The simplest and easiest way to generate your jsonpaths is to use our feature called the Connector-snake. Please see the main page for more details.

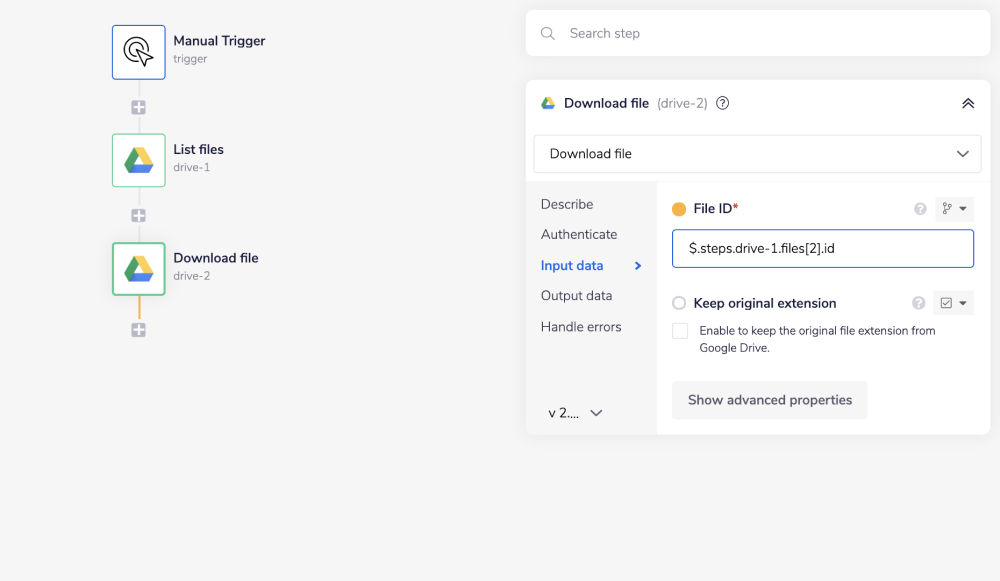
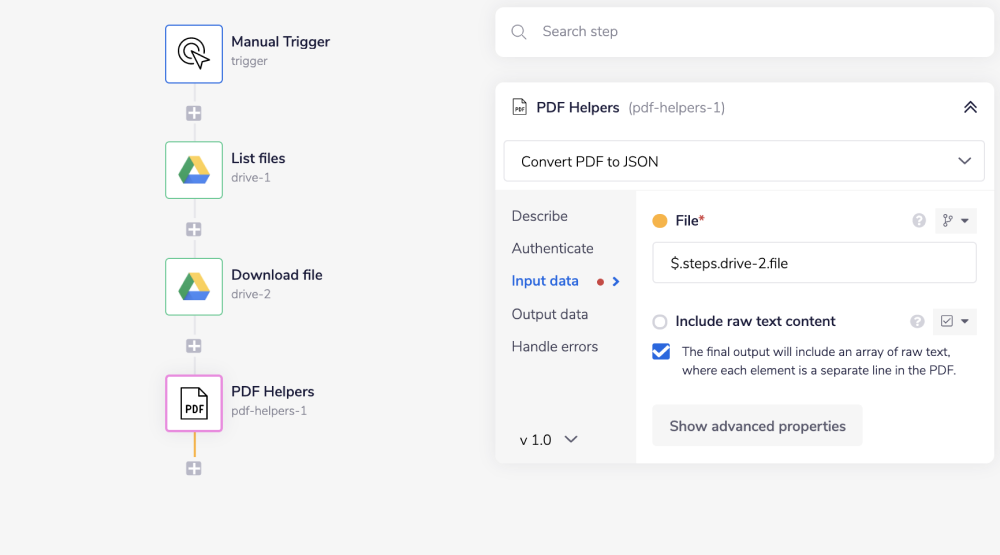
4. Convert chosen file to PDFCopy
Find 'PDF helpers' connector in the 'Helpers' section of the panel and add it to your forth step. Choose 'Convert PDF to JSON' operation. To set the connector downloaded we use the $.steps.drive-2.file jsonpath to pull it from 'Download file' step. Set the operation to 'Convert PDF to JSON'. 'Include raw tetx content' checkbox will include all non-interactive text content from te initial PDF file.

Click 'Run workflow' to see your result and go to the debug tab to see the result

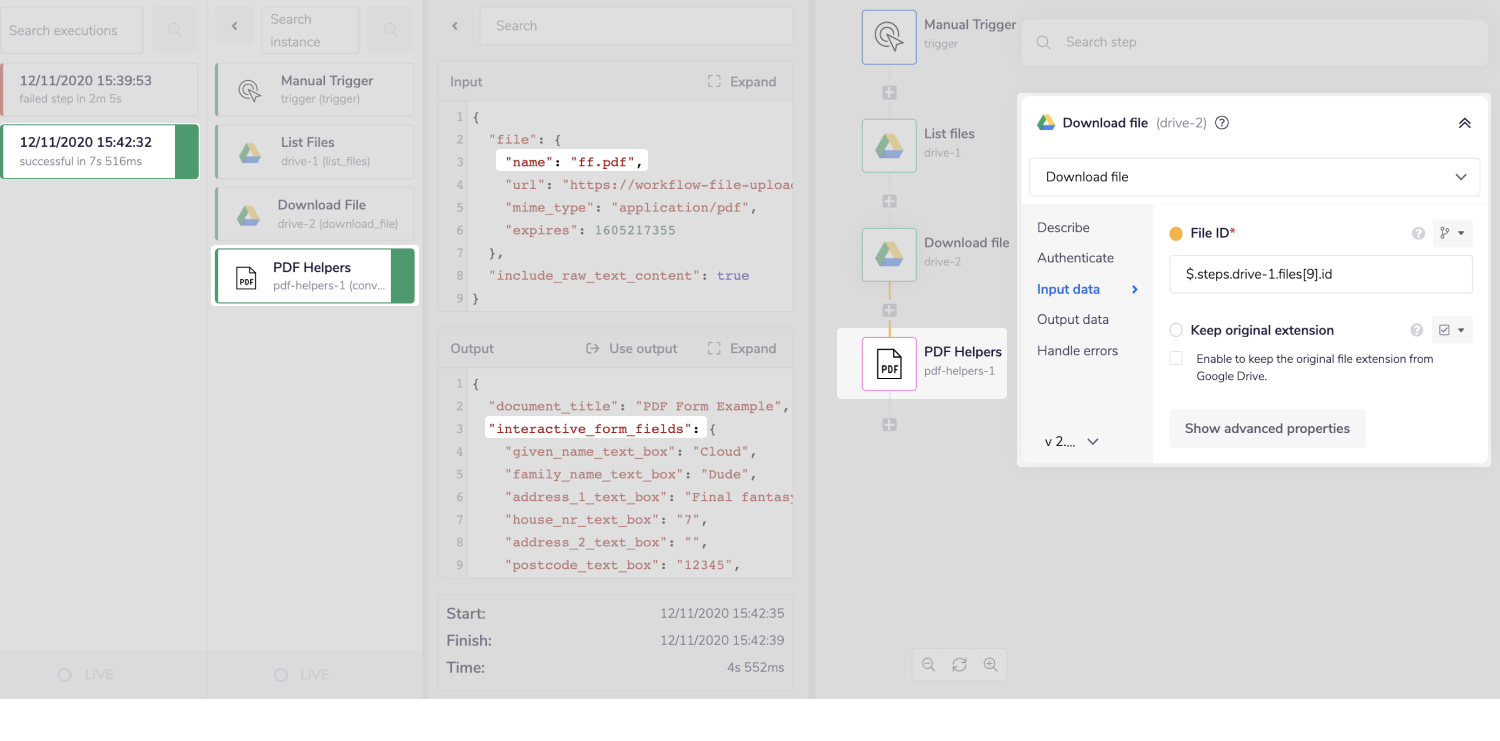
Let's break down our result output:
document_title - The title from the original PDF document
interactive_form_fields - The user input from the ordinal document (forms, dropdowns etc)
raw_text_content - Everything but user input from the original document, deviled by new lines
Congratulations! You just created a fully functional workflow.
BEST PRACTICES: Whenever you do decide to create your own workflow, be sure to check out some of our key articles such as: